BigQuery MCP Server: Secure Setup for Claude & AI Agents (2026)
The BigQuery MCP server lets Claude, Cursor, ChatGPT, and AI agents run natural-language SQL across your BigQuery datasets. Here's the official setup, the real security risks, and how to govern it with DLP-grade redaction at the MCP layer.
The BigQuery MCP server is the path for AI agents (Claude, Cursor, ChatGPT, Gemini, custom agents) to run natural-language-to-SQL across your BigQuery datasets via the Model Context Protocol — listing datasets and schemas, querying tables, and summarizing results across every dataset the connecting credential can read.
Google ships two official paths: the fully managed remote BigQuery MCP server (an HTTP endpoint, OAuth 2.0 + IAM, no API keys) and the open-source MCP Toolbox for Databases you self-host. Both expose tools like list_dataset_ids, get_table_info, and execute_sql.
The risk: one natural-language prompt becomes a SQL query that can scan an entire dataset and return regulated columns — PII, PHI, card numbers, financial records — as raw rows into the model's context. IAM dataset grants are usually broad, results come back in bulk, and nothing in the path redacts them.
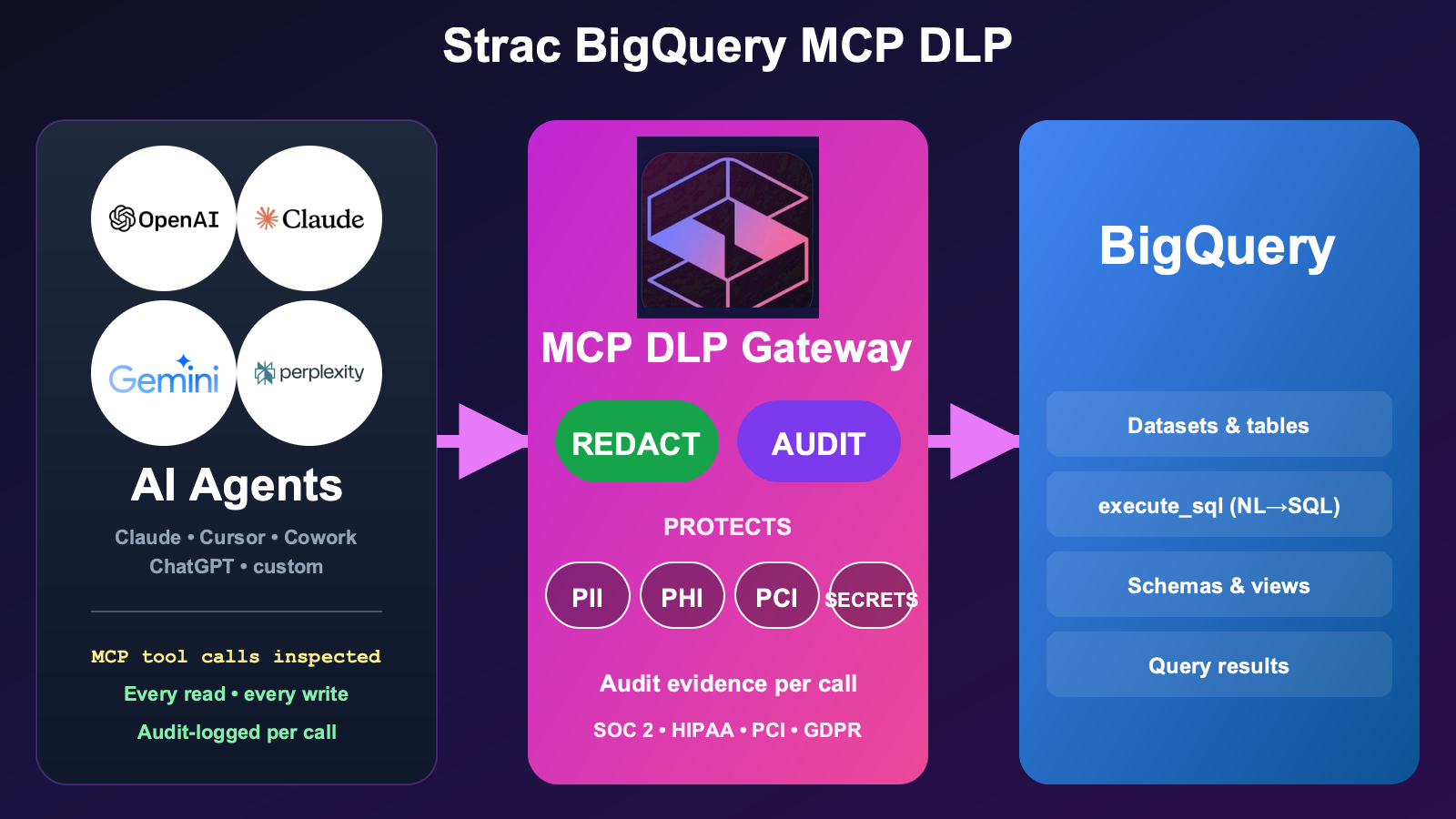
Strac BigQuery MCP DLP is the governance layer for AI-agent access to BigQuery. Strac governs every tool call between the agent and BigQuery: it controls what each agent can reach and run (allow/block, plus approval on high-risk queries and writes), protects sensitive columns with redaction, masking, tokenization, and vaulting — including column-level — and logs every call as audit evidence, mapped to SOC 2 / HIPAA / PCI / GDPR / EU AI Act / ISO 42001. One control plane across every dataset and table.
Setup is agentless and under 10 minutes per project. No application code changes, no agent SDK changes, no BigQuery re-permissioning.
What Is the BigQuery MCP Server?
The BigQuery MCP server is a Model Context Protocol implementation that exposes BigQuery's query engine and metadata API as a standardized set of tools to AI agents. Once connected, an agent like Claude can enumerate datasets, read table schemas, generate SQL from plain English, execute that SQL, and summarize the rows that come back — turning your data warehouse into something an AI client can reason over directly.
Google offers two official routes, both documented at Google Cloud's BigQuery MCP guide. The fully managed remote server runs on Google's infrastructure and presents an HTTP endpoint your AI client points at; it authenticates with OAuth 2.0 over IAM and explicitly does not accept API keys. The self-hosted MCP Toolbox for Databases (the googleapis/mcp-toolbox open-source project) runs as a binary you deploy yourself, supports custom parameterized queries, and covers BigQuery alongside dozens of other data sources. Either way the core tool set is consistent: list_dataset_ids, list_table_ids, get_dataset_info, get_table_info, and execute_sql (with a read-only variant).
From the analyst's perspective, the AI agent suddenly knows the warehouse — it can answer a business question without anyone writing SQL by hand. From the security perspective, the agent now holds query access to every dataset the connecting identity can read, and the rows it pulls land directly in the model's context window.
That's the value. It's also where security teams need a control layer.
What AI Agents Can Actually Do With BigQuery MCP
Once the BigQuery MCP server is connected, an agent works your datasets the way an analyst would — except it writes the SQL itself from a plain-English question. Bounded by the IAM identity it runs as, it can:
Answer business questions in plain English — "What was net revenue by region last quarter, excluding refunds?" becomes a generated SQL statement executed live against your tables, not a stale dashboard export.
Explore the warehouse on its own — call list_dataset_ids and get_table_info to discover what datasets and columns exist, then decide which tables to query without a human pointing the way.
Summarize and interpret result sets — run a query, pull back the rows, and describe the trend, the outlier, or the forecast in a sentence the requester can act on.
Run cross-dataset analysis — join a customer dataset against a transactions dataset against an events dataset in a single query, reasoning over relationships that span the whole warehouse.
Feed downstream automation — return numbers that trigger the next step in an agentic workflow: a report, an alert, a write-back to another table.
Every one of those actions runs through BigQuery's own job engine and IAM permissions — which is what makes it genuinely useful, and exactly why the regulated columns it can reach need an inspection layer sitting in the tool-call path.
The Real Security Risks of the BigQuery MCP Server
The risks fall into four categories that every healthcare, fintech, and enterprise security team should price into the deployment.
1. One prompt can scan an entire dataset. Natural-language-to-SQL has no instinct for least privilege. "Show me our customers" can compile to a SELECT * across a table holding millions of rows of PII. The execute_sql tool runs it, and the regulated columns return raw to the agent — no WHERE not_sensitive = true clause exists.
2. IAM dataset grants are usually too broad. BigQuery access is commonly granted at the dataset or project level — Data Viewer on a whole dataset, not column by column. The connecting identity can typically read far more than any single task needs, and the MCP server faithfully serves all of it. The blast radius is the credential's entire footprint, not the question that was asked.
3. Results come back in bulk. A single execute_sql call returns thousands of rows in one response. SSNs, card numbers, clinical identifiers, and financial figures arrive as a structured payload that flows straight into the model's context window — exactly the high-volume, high-sensitivity pattern that turns one query into a reportable disclosure.
4. Schemas and metadata leak sensitive structure. Before a single row is read, get_table_info exposes column names like ssn, dob, card_pan, or diagnosis_code. Metadata tells an agent — or an attacker steering one through prompt injection — precisely where the regulated data lives and how to query it.
The traditional DLP a company already runs — at the network edge, on the file share, inside the cloud-native rule engine — does not sit in the MCP path. The query result goes straight from BigQuery into the AI agent's context window. That reach is exactly why each agent's access and queries against BigQuery must be governed: controlled (what it can reach and run), the sensitive columns it touches protected, and every call audited. That is where Strac BigQuery MCP DLP lives.
Strac's BigQuery MCP DLP is the governance layer that sits between AI agents and the BigQuery MCP server. Strac governs every tool call: it sees exactly which datasets, tables, and columns each agent reaches in BigQuery, controls what it can run (allow, block, or require approval on high-risk queries, exports, and writes), protects the sensitive columns it touches by redacting, masking, tokenizing, or vaulting them, and logs every call as audit evidence. Non-sensitive, in-policy queries flow through untouched.
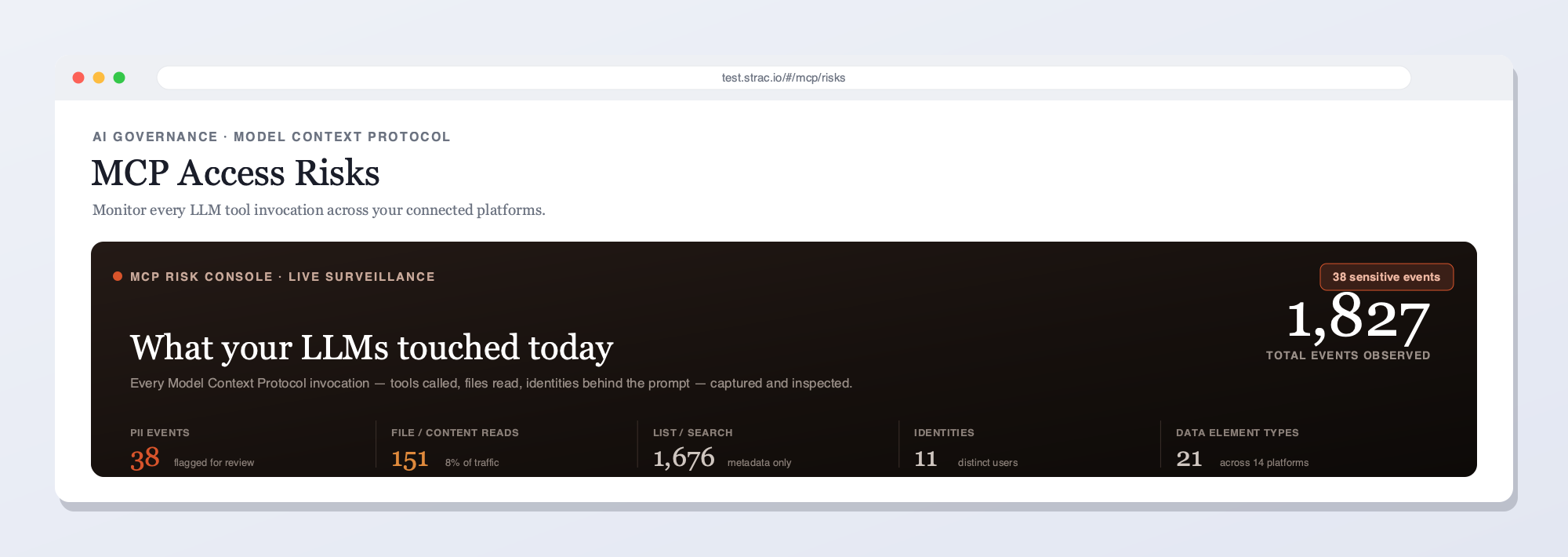
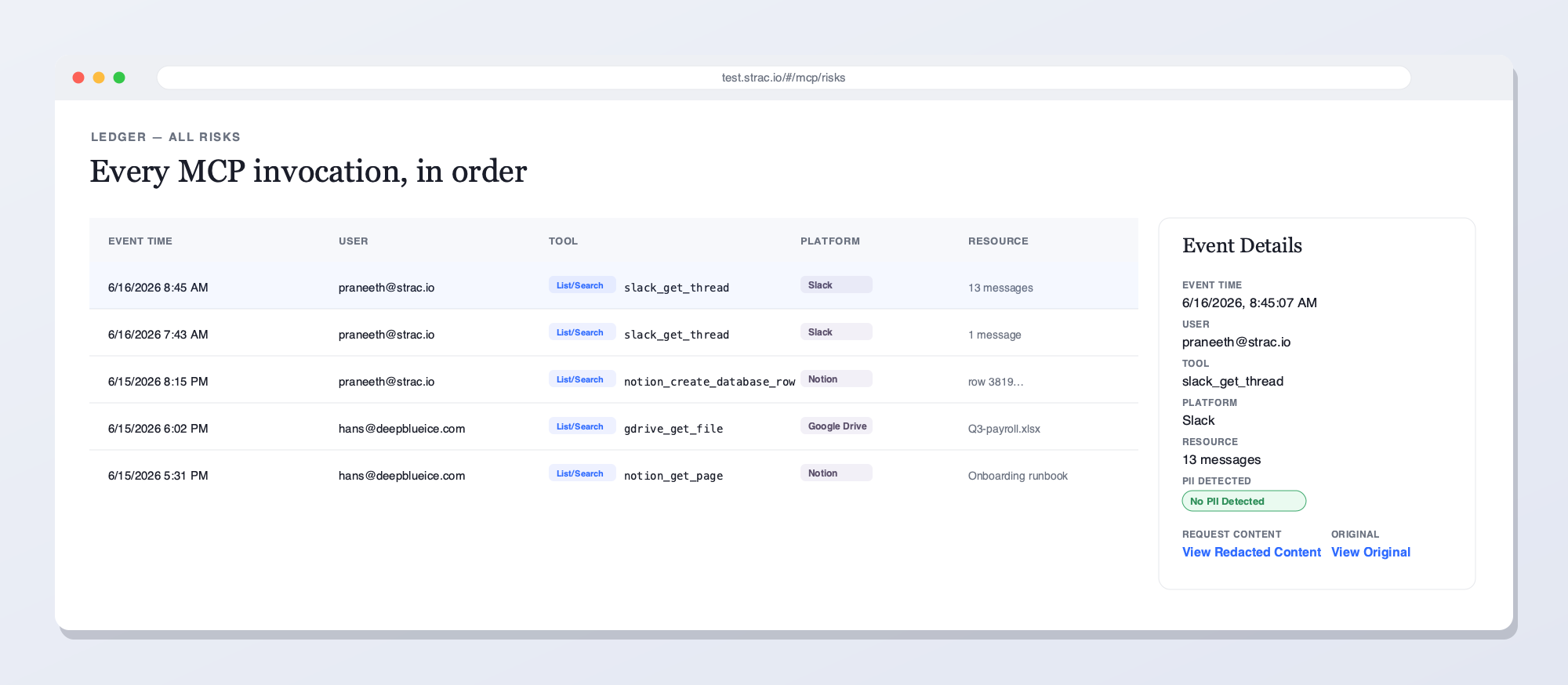
The Strac BigQuery MCP DLP gateway intercepts every tool call between any AI agent (Claude, Cursor, Gemini, ChatGPT, custom) and the BigQuery MCP server. PII, PHI, PCI, and financial columns are redacted before the AI agent ever reads a single returned row.Strac's live MCP Access console — every AI agent tool call touching BigQuery and your other connected platforms, captured and inspected for sensitive data in real time. See what your LLMs reached for, who prompted, and what was flagged.Every MCP invocation in order — user, tool, platform, and the sensitive data found — with redacted vs. original content and a full audit trail. This is what Strac shows on BigQuery that access-only gateways can't: the data in each call, not just the call.
Strac vs. access-only MCP gateways
A gateway that only governs access can tell you an agent called a BigQuery tool — but not that the PII in a returned dataset came back in the response. Strac inspects the content of every call, remediates the sensitive data — redact, mask, block, or delete — before the model sees it, and still logs the full access trail. You get access control and the data layer, in one place.
What Strac does on every BigQuery tool call
One inline pass over each MCP response — five actions, enforced by your policy:
Detect — finds PII in a returned dataset and any PII, PHI, PCI, secrets, or source code in the payload, including text inside images via OCR.
Redact or mask — replaces the sensitive elements inline, so the agent still gets its answer and the model never sees the raw data.
Block or require approval — stops a high-risk action like a large query or export, or routes it for sign-off before it runs.
Alert — notifies your team and streams the event to your SIEM (Datadog, Splunk, Chronicle) in real time.
Audit — logs who, which agent, which tool, what data, and the action taken — evidence mapped to SOC 2, HIPAA, GDPR, and ISO 42001.
What this looks like in practice:
Query results are filtered column-level. When the agent calls execute_sql and the result set contains SSNs / credit cards / emails / PHI / account numbers, Strac inspects the returned rows and redacts, masks, or tokenizes the sensitive columns inline, then passes the clean result to the agent. The analysis still runs; the regulated values never enter the model context.
High-risk queries are guardrailed. A SELECT * against a known PII table, a query that exports in bulk, or any execute_sql write can require approval or be blocked outright by policy — before it ever runs against BigQuery.
Metadata exposure is controlled.get_table_info and list_dataset_ids responses are governed too, so sensitive schema and dataset structure isn't handed to the agent (or a prompt-injection attacker) by default.
Every invocation is logged. AI client, user, tool name, dataset and table accessed, SQL run, data classes detected, columns redacted, vault references, disposition. The log is the SOC 2 / HIPAA / PCI / GDPR audit evidence — produced automatically.
Policy is contextual. Different datasets, different policies. Strac maps to your existing data classification, not an MCP-specific silo.
Two things separate a real scrubbing gateway from a checkbox. It governs the MCP tools you build yourself — the ones you expose to employees and customers — as thoroughly as the BigQuery connector. And it hands you the redaction controls directly: mask, redact, tokenize, or write a custom regex for your own formats, with a managed classifier doing the detection so there's no Presidio or Bedrock rig for your team to run.
The same Strac MCP DLP layer covers warehouse siblings like Snowflake MCP, Databricks MCP, and Postgres MCP — one control plane across every place AI agents query your regulated data.
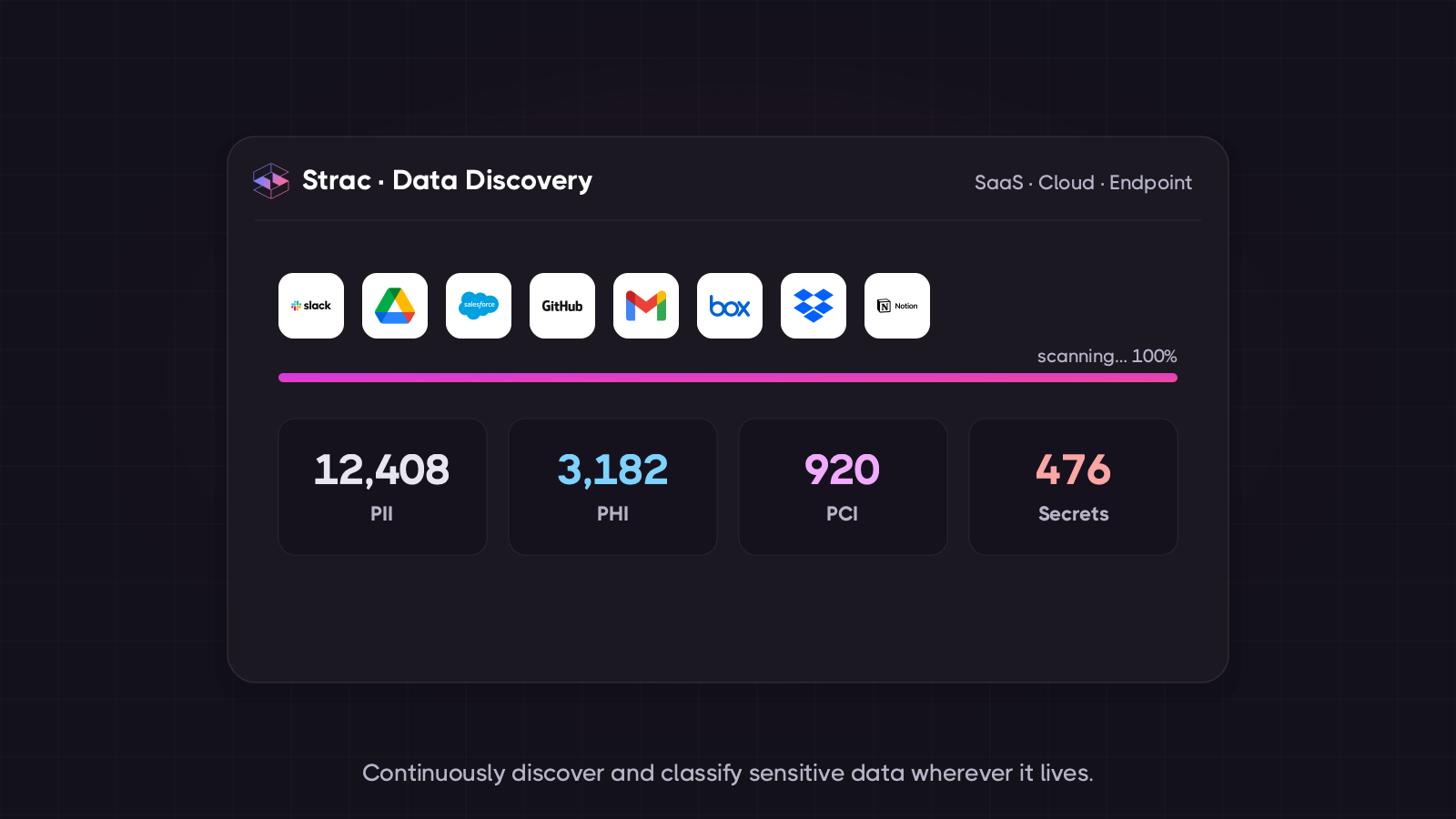
✨ Strac Native BigQuery DLP — The Companion to MCP DLP
Strac natively discovers and classifies the regulated columns inside your BigQuery warehouse before any agent queries them — the companion to BigQuery MCP DLP that maps where sensitive data lives.
MCP DLP protects the AI-agent surface. Strac's native BigQuery DLP protects the data-at-rest surface — the same warehouse, but scanned continuously where the regulated data actually lives. Most enterprises run both: native DSPM-for-AI discovery to know which columns hold sensitive data, MCP DLP to govern the agent queries that read them. Together they cover every path regulated data can take in and out of BigQuery.
What Strac's native BigQuery DLP includes:
Continuous discovery and classification of PII, PHI, PCI, and financial data across every BigQuery dataset, table, and column
Column-level inspection — Strac classifies which columns hold SSNs, card numbers, health data, and customer identifiers, so you have a live sensitivity map of the warehouse
Schema-aware scanning that flags newly added sensitive columns as datasets evolve
Risk scoring on over-permissioned datasets — surfacing where IAM grants expose more regulated data than the workload needs
Tokenization and vault-redaction so sensitive column values can be protected while the table stays usable for analytics
Audit logs mapped per finding to SOC 2 CC6, HIPAA Security Rule, PCI Req. 3/4/7/10, and GDPR
This native sensitivity map is what makes the MCP DLP layer precise: Strac already knows which BigQuery columns are regulated, so query-time redaction is surgical rather than guesswork.
For the broader integration catalog — every SaaS, cloud warehouse, browser, and endpoint surface Strac covers — see strac.io/integrations.
✨ See Strac MCP DLP in Action
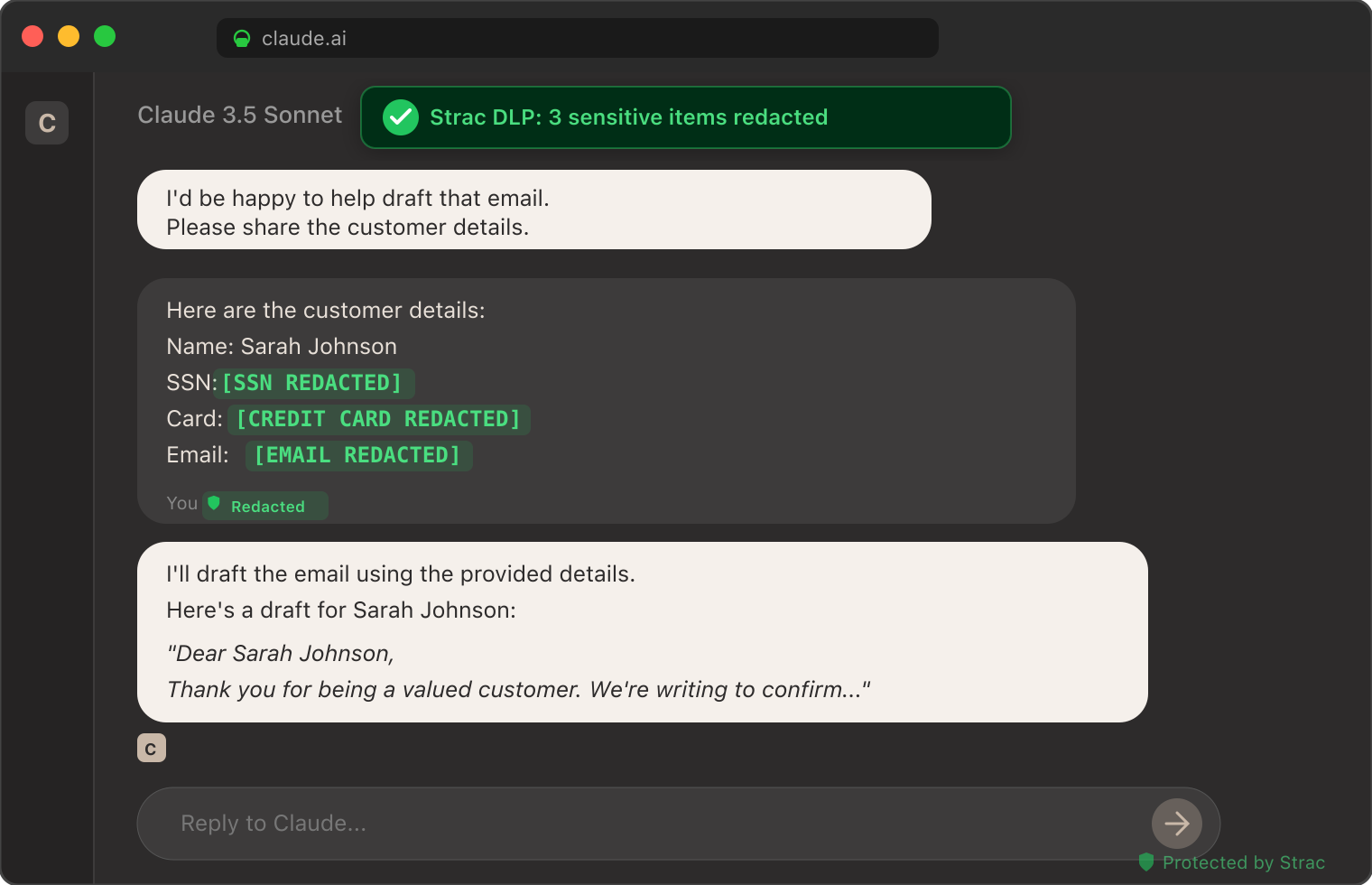
The screenshot below shows Strac's MCP DLP redacting sensitive data from a real Claude session — patient identifiers, customer emails, and credit card numbers tokenized inline before the model received the data. The same inspection pattern runs on every BigQuery MCP query result routed through Strac, column by column.
Strac DLP at work inside a Claude conversation: sensitive elements tokenized inline before the model sees them. The same pattern runs at the MCP layer for every BigQuery query result.
How to Set Up Strac BigQuery MCP DLP
Setup is agentless and takes under 10 minutes.
Authorize Strac with your Google Cloud project via OAuth. Strac honors BigQuery's IAM model — it only sees the datasets and tables the connecting identity can see, and inherits the same Data Viewer / Job User scopes the BigQuery MCP server uses.
Configure the MCP gateway endpoint. Strac issues an MCP server endpoint that drops into your AI client's MCP configuration in place of the raw BigQuery endpoint. For Claude Desktop:
json
"mcpServers": {
"bigquery": {
"url": "https://mcp.strac.io/bigquery",
"auth": { "type": "bearer", "token": "<your-strac-token>" }
}
}
For Cursor, Gemini, OpenAI Agents, custom agents — same endpoint, same auth.
Pick your policy. Out-of-the-box templates for SOC 2, HIPAA, PCI, GDPR. Custom policies (dataset-level, column-level, data-class-level, query-level) take minutes to configure.
Done. Every MCP tool call between your agent and BigQuery now flows through the Strac gateway. No application code changes. No agent code changes. The audit log starts populating immediately.
Compliance Coverage Out of the Box
The same Strac BigQuery MCP DLP control produces evidence mapped to every major compliance framework — with HIPAA and GDPR front of mind for any warehouse holding patient or EU-resident data.
Framework
What Strac BigQuery MCP DLP Satisfies
HIPAA
§164.312(b) (audit controls over query access), §164.502(b) (minimum necessary — column-level redaction enforces it at query time), §164.514 (de-identification of returned PHI), §164.528 (accounting of disclosures)
GDPR
Art. 5 (data minimization and purpose limitation on every query), Art. 25 (data protection by design), Art. 30 (records of processing — the per-query audit log), Art. 32 (security of processing)
SOC 2
CC6.6 (unauthorized data exposure), CC6.7 (restricted transmission of data to external systems), CC7.2 (monitoring for anomalies including AI query activity)
PCI DSS v4.0.1
Req. 3.3 (PAN masking in returned columns), Req. 4.x (encryption in transit), Req. 7 (least privilege on dataset access), Req. 10 (log every query)
EU AI Act
Art. 10 (data governance for high-risk AI systems)
ISO/IEC 42001
Clause 6.1.4 (risk treatment), Clause 8.4 (operational controls), Annex A.7 (data for AI systems)
For the broader AI-data-governance program this sits inside, see the AI DLP pillar.
🌶️ Spicy FAQs for BigQuery MCP Server
What is the BigQuery MCP server?
The BigQuery MCP server is a Model Context Protocol implementation that lets AI agents (Claude, Cursor, ChatGPT, Gemini, custom agents) run natural-language-to-SQL across your BigQuery datasets via standardized tool calls. It's how an AI client lists datasets, reads table schemas with get_table_info, executes SQL with execute_sql, and summarizes the results — over every dataset the connecting IAM identity can read.
Is the BigQuery MCP connector the same as the BigQuery MCP server?
Yes, identical. Developers reading Google's docs see "BigQuery MCP server"; Claude surfaces the BigQuery connector in its directory. Both run NL→SQL over your datasets and tables, and Strac's BigQuery MCP connector redacts regulated columns before results reach the model.
BigQuery MCP vs Gemini in BigQuery — what's the difference?
Gemini in BigQuery is Google's built-in assistant: it runs inside the BigQuery console, helps you write and explain SQL, and keeps the data within Google's boundary. The BigQuery MCP server points the other direction — it exposes BigQuery to external agents (Claude, Cursor, ChatGPT, custom) over the open Model Context Protocol, so the AI client your team already uses can query the warehouse directly. Gemini in BigQuery keeps the query and its results inside Google's native guardrails; MCP lets any agent reach in, and the result rows leave those guardrails the moment they return to the client. That hand-off is exactly where Strac BigQuery MCP DLP inspects and redacts — column by column.
Is the BigQuery MCP server safe to use with sensitive data?
By itself, no — not without an additional DLP layer. The BigQuery MCP server honors the connecting identity's IAM permissions but returns whatever that identity can query, including PII, PHI, card numbers, and financial records, in bulk. Because IAM grants are usually dataset-wide, one natural-language prompt can scan far more regulated data than the question needed. For enterprise use with regulated data, you need an MCP-layer DLP control like Strac BigQuery MCP DLP that inspects and redacts every query result before rows reach the AI model.
How is Strac BigQuery MCP DLP different from BigQuery's built-in protections?
BigQuery's built-in protections operate at the storage and policy layer — IAM roles, column-level security, dynamic data masking, policy tags. Those are powerful, but they're configured per identity and don't sit in the MCP tool-call path the way an inspection gateway does. Strac is purpose-built for that path: it inspects every query result before rows reach the AI agent's context window, applies redaction based on a live sensitivity map of your warehouse, and produces a per-query audit log — with detection breadth (PII / PHI / PCI / financial / secrets) that travels with the agent rather than depending on every dataset being perfectly tagged in advance.
Does Strac BigQuery MCP DLP work with Claude, Cursor, Gemini, ChatGPT, and custom agents?
Yes. Strac exposes a standard MCP gateway endpoint, so any MCP-aware AI client routes tool calls through it with one configuration change. No SDK changes, no application code changes.
What sensitive data types does Strac detect in BigQuery MCP query results?
PII (SSN, driver's license, passport, address, phone, email), PHI (clinical notes, MRN co-occurrence, ICD-10 codes adjacent to identifiers, lab values), PCI (full and partial card numbers via Luhn check), financial data (account and routing numbers, balances), credentials (API keys, GCP / AWS / Azure access keys, OAuth tokens, JWTs, private keys), and custom detectors trained on your internal data classifications. Detection runs across returned rows, column metadata, and schema responses.
Can Strac block a query before it runs against BigQuery?
Yes. Policy can require approval on, or outright block, high-risk calls — a SELECT * against a known PII table, a bulk export, or any execute_sql write — before the job ever reaches BigQuery. Lower-risk, in-policy queries flow through untouched.
How long does Strac BigQuery MCP DLP take to deploy?
Under 10 minutes for the first project. OAuth Strac into your Google Cloud project, paste the Strac MCP gateway endpoint into your AI client's config, pick a policy template, done. No agents to install, no BigQuery re-permissioning, no application code changes.
Can I see what an AI agent queried in my warehouse?
Yes. Strac produces a per-call audit log: timestamp, AI client identity, user, tool invoked, dataset and table accessed, SQL executed, data classes detected, columns redacted, vault references, disposition. The log is queryable in the Strac console and exportable to your SIEM. This is the evidence trail SOC 2, HIPAA, PCI, and GDPR auditors will ask about for AI-agent activity in BigQuery.
The Bottom Line
The BigQuery MCP server is rapidly becoming the way AI agents query enterprise data warehouses. That surface contains every category of regulated and proprietary data your organization has — and unlike a CRM, a single natural-language prompt can scan the whole dataset at once. Running BigQuery MCP in 2026 without an MCP-layer DLP control is not a question of if the first over-broad query reaches your security team; it's when.
Strac BigQuery MCP DLP gives you the governance layer, the column-level protection, the audit evidence, and the framework-agnostic compliance coverage so you can let your team query the warehouse with Claude, Cursor, Gemini, ChatGPT, and any future AI client without making each one a separate security exception.
If you are running — or about to run — BigQuery MCP in production, book a 30-minute demo. We'll walk through the architecture, the policy templates, and a deployment plan for your specific BigQuery project and AI clients.
The BigQuery MCP server is a Model Context Protocol implementation that lets AI agents (Claude, Cursor, ChatGPT, Gemini, custom agents) run natural-language-to-SQL across your BigQuery datasets via standardized tool calls. It's how an AI client lists datasets, reads table schemas with get_table_info, executes SQL with execute_sql, and summarizes the results — over every dataset the connecting IAM identity can read.
Is the BigQuery MCP connector the same as the BigQuery MCP server?
Yes, identical. Developers reading Google's docs see "BigQuery MCP server"; Claude surfaces the BigQuery connector in its directory. Both run NL→SQL over your datasets and tables, and Strac's BigQuery MCP connector redacts regulated columns before results reach the model.
BigQuery MCP vs Gemini in BigQuery — what's the difference?
Gemini in BigQuery is Google's built-in assistant: it runs inside the BigQuery console, helps you write and explain SQL, and keeps the data within Google's boundary. The BigQuery MCP server points the other direction — it exposes BigQuery to external agents (Claude, Cursor, ChatGPT, custom) over the open Model Context Protocol, so the AI client your team already uses can query the warehouse directly. Gemini in BigQuery keeps the query and its results inside Google's native guardrails; MCP lets any agent reach in, and the result rows leave those guardrails the moment they return to the client. That hand-off is exactly where Strac BigQuery MCP DLP inspects and redacts — column by column.
Is the BigQuery MCP server safe to use with sensitive data?
By itself, no — not without an additional DLP layer. The BigQuery MCP server honors the connecting identity's IAM permissions but returns whatever that identity can query, including PII, PHI, card numbers, and financial records, in bulk. Because IAM grants are usually dataset-wide, one natural-language prompt can scan far more regulated data than the question needed. For enterprise use with regulated data, you need an MCP-layer DLP control like Strac BigQuery MCP DLP that inspects and redacts every query result before rows reach the AI model.
How is Strac BigQuery MCP DLP different from BigQuery's built-in protections?
BigQuery's built-in protections operate at the storage and policy layer — IAM roles, column-level security, dynamic data masking, policy tags. Those are powerful, but they're configured per identity and don't sit in the MCP tool-call path the way an inspection gateway does. Strac is purpose-built for that path: it inspects every query result before rows reach the AI agent's context window, applies redaction based on a live sensitivity map of your warehouse, and produces a per-query audit log — with detection breadth (PII / PHI / PCI / financial / secrets) that travels with the agent rather than depending on every dataset being perfectly tagged in advance.
Discover & Protect Data on SaaS, Cloud, Generative AI
Strac provides end-to-end data loss prevention for all SaaS and Cloud apps. Integrate in under 10 minutes and experience the benefits of live DLP scanning, live redaction, and a fortified SaaS environment.

.webp)












.gif)
