Redshift MCP Server: Secure Setup for Claude & AI Agents (2026)
The Amazon Redshift MCP server lets Claude, Cursor, ChatGPT, and AI agents query your data warehouse in plain English. Here's the setup, the real security risks of agent access to a warehouse, and how to govern it with column-level redaction at the MCP layer.
The Amazon Redshift MCP server lets AI agents (Claude, Cursor, ChatGPT, Perplexity, custom agents) run SQL against your Redshift data warehouse through the Model Context Protocol — listing clusters, schemas, and tables, and executing analytical queries in plain English.
The official server is maintained by AWS Labs, runs queries read-only by default (single-statement, writes rejected), and authenticates through AWS IAM and the Redshift Data API. Read-only is the right default — but it does nothing about what those reads return.
The risk here is different from a transactional database. Redshift is the warehouse: the place CRM, billing, product, and support data are joined together. One agent query can surface regulated data that was never co-located operationally — and a columnar, massively-parallel scan returns millions of rows cheaply and fast.
Strac Redshift MCP DLP is the governance layer for AI-agent access to Redshift. Strac sees every query, controls which schemas and columns an agent can reach and caps bulk exports, protects sensitive columns with redaction, masking, tokenization, and vaulting, and proves every call as audit evidence mapped to SOC 2 / HIPAA / PCI / GDPR. Redaction is part of it, not the whole of it.
Setup is agentless and under 10 minutes — no application changes, no warehouse migration, no re-grant.
What Is the Amazon Redshift MCP Server?
The Amazon Redshift MCP server is a Model Context Protocol implementation that exposes a Redshift data warehouse to AI agents as a set of standardized tools. Once connected, an agent like Claude can discover your clusters and serverless workgroups, browse databases, schemas, tables, and columns, and run read-only SQL — turning the warehouse into something an AI client can query in natural language.
The official redshift-mcp-server, maintained by AWS Labs and documented here, takes a deliberately conservative stance: queries run read-only by default, wrapped so that writes and multi-statement SQL are rejected. It reaches the warehouse through the Redshift Data API and authenticates with AWS IAM, so the agent's reach is bounded by the IAM role and the database grants you give it. (An older aws-samples Redshift MCP server exists but is superseded — standardize on the AWS Labs one.)
From the analyst's seat, the agent suddenly understands the warehouse — it answers questions across joined datasets without anyone building a dashboard. From the security seat, the agent now holds query access to the single most concentrated store of regulated data your organization has.
That's the value. It's also exactly where a control layer belongs.
What AI Agents Can Actually Do With Redshift MCP
Point an agent at the Redshift MCP server and it works the warehouse directly, turning plain-English questions into read-only SQL against the schemas the connected IAM role and DB user can touch. In practice it can:
Answer analytical questions in plain English — "What's the 90-day retention by acquisition channel for enterprise accounts?" becomes a live query across joined fact and dimension tables.
Discover the warehouse itself — list_clusters, list_databases, list_schemas, list_tables, and list_columns let the agent map an unfamiliar warehouse before it queries.
Join across every source you've centralized — CRM, billing, product telemetry, and support tickets all live in one place; the agent joins across them in a single query.
Run heavy aggregations on demand — cohort analysis, revenue rollups, funnel math — computed against billions of rows with Redshift's columnar engine.
Reach into the data lake — where Redshift Spectrum external tables are defined, queries extend out to S3.
Every one of those runs through Redshift's SQL engine and the privileges of the IAM role and DB user you connected — which is what makes it powerful, and exactly why the regulated data those queries return needs an inspection layer in the tool-call path.
The Real Security Risks of the Redshift MCP Server
Read-only by default removes the write risk — but a warehouse has its own, sharper exposure. Five categories every healthcare, fintech, and enterprise security team should price in:
1. It's the most concentrated regulated data you have. A warehouse exists to centralize and join data from every source. PII, PHI, and financial records that were siloed in separate systems are now in one place, joinable in a single query. The blast radius of one bad query is the whole business, not one table.
2. Columnar, massively-parallel scans return data in bulk — cheaply. Redshift is built to scan billions of rows fast. "Show me every customer with their email, plan, and lifetime value" is a valid, quick query that streams millions of regulated rows straight into the model's context window — far beyond what any human would export.
3. There is no column filter in the path. SQL has no WHERE not_regulated = true. Whatever the connected role can read, a wide SELECT returns — and the agent can't tell a regulated column from a benign one. Read-only stops writes; it does nothing to stop plaintext PII flowing back in the result set.
4. Spectrum and data sharing extend the reach. Redshift Spectrum external tables push queries out to S3, and cross-account data sharing widens the surface beyond the cluster you connected. The agent's reach can quietly exceed the warehouse itself.
5. Cost and credit exposure. On Redshift Serverless, an unbounded agent query consumes RPU-seconds; on Spectrum, it's billed by bytes scanned. A poorly-shaped agent query is both a data-exposure event and a bill.
As AWS puts it in its own guidance on secure AI-agent access: "Any permission you grant to an agent can be exercised, regardless of your intended use case." The DLP a company already runs doesn't sit in the SQL path between an agent and Redshift — the query result goes straight from the warehouse into the AI agent's context window. That reach is precisely why each agent's access must be governed: controlled (which schemas and columns it can touch, and how much it can pull), the sensitive data it returns protected, and every query audited. That is where Strac Redshift MCP DLP lives.
Strac's Redshift MCP DLP is the governance layer that sits between AI agents and the Redshift MCP server. Strac governs every query: it sees exactly what each agent runs, controls what it can reach and how much it can pull, protects the sensitive columns it touches, and logs every call as audit evidence. In-policy, non-sensitive queries flow through untouched.
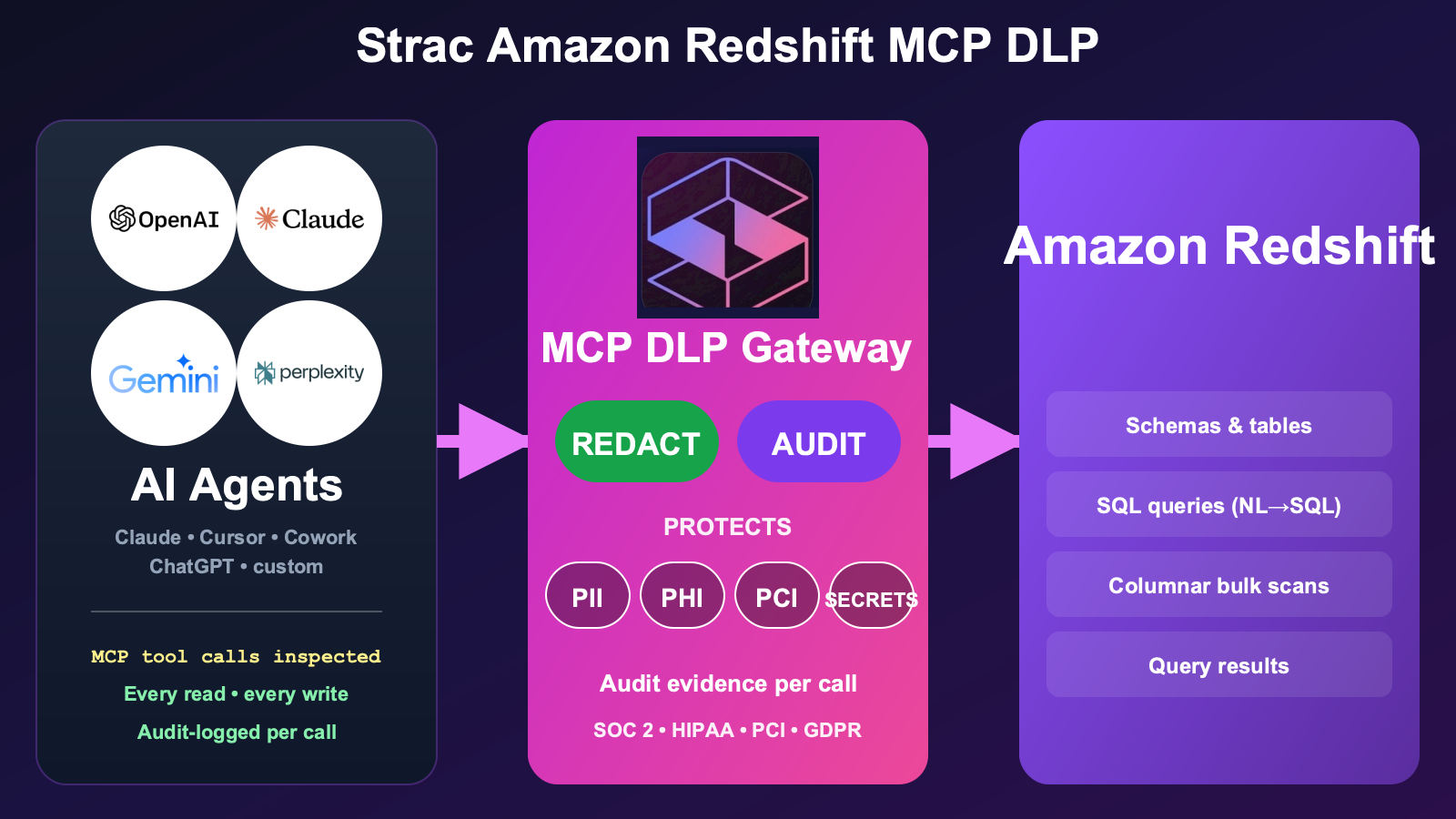
The Strac Redshift MCP DLP gateway sits between any AI agent (Claude, Cursor, ChatGPT, custom) and the Redshift MCP server. It scopes which schemas and columns the agent can reach, caps bulk scans, and redacts regulated columns before any row reaches the model.
What this looks like in practice, mapped to See / Control / Protect / Prove:
See — Strac surfaces every query an agent runs: which AI client, which user, which schemas and columns it touched, how many rows came back, and which data classes were present. The opaque "the agent queried the warehouse" becomes a per-query record.
Control — Strac scopes access at the schema and column level and caps result volume. You allow an agent to read the analytics schema but never the pii or billing columns, and you cap how many rows a single query can pull — so a "select everything" prompt can't vacuum millions of regulated rows.
Protect — Strac applies column-level redaction, masking, tokenization, and vaulting on the way back. An email column returns masked, a card_number tokenized, a ssn redacted — the agent still gets a usable result set for its analysis, but the regulated values never enter the model context.
Prove — every query is logged with the data classes detected, the controls applied, and the disposition. The log is the SOC 2 / HIPAA / PCI / GDPR audit evidence for AI-agent warehouse activity — produced automatically.
✨ Strac Native Redshift DLP — The Companion to MCP DLP
Strac natively discovers and classifies the regulated columns inside your Redshift warehouse before any agent queries them — the companion to Redshift MCP DLP that maps where sensitive data lives.
MCP DLP governs the AI-agent query surface. Strac's native Redshift DLP governs the data at rest — the same warehouse, but discovered and classified so you know where the regulated columns are before any agent ever queries them. This is DSPM for Redshift, and most teams run both: native discovery to map and label the sensitive data, MCP DLP to govern how agents reach it.
What Strac's native Redshift DLP includes:
Continuous discovery and classification of PII, PHI, PCI, and financial data across every database, schema, table, and column
Column-level labeling — Strac identifies which columns hold SSNs, card numbers, health data, and customer identifiers, so policy can target them precisely
Sampling at depth — Strac inspects column contents, not just names, so a notes column holding clinical data or a props field hiding tokens is caught
A live data map of where regulated data sits, feeding directly into the MCP DLP column-level controls
Audit-ready findings mapped to SOC 2 CC6, HIPAA Security Rule, PCI Req. 3/7/10, and GDPR
For the broader practice this sits inside, see DSPM for AI. For every SaaS, cloud, database, and endpoint surface Strac covers, see strac.io/integrations.
✨ See Strac MCP DLP in Action
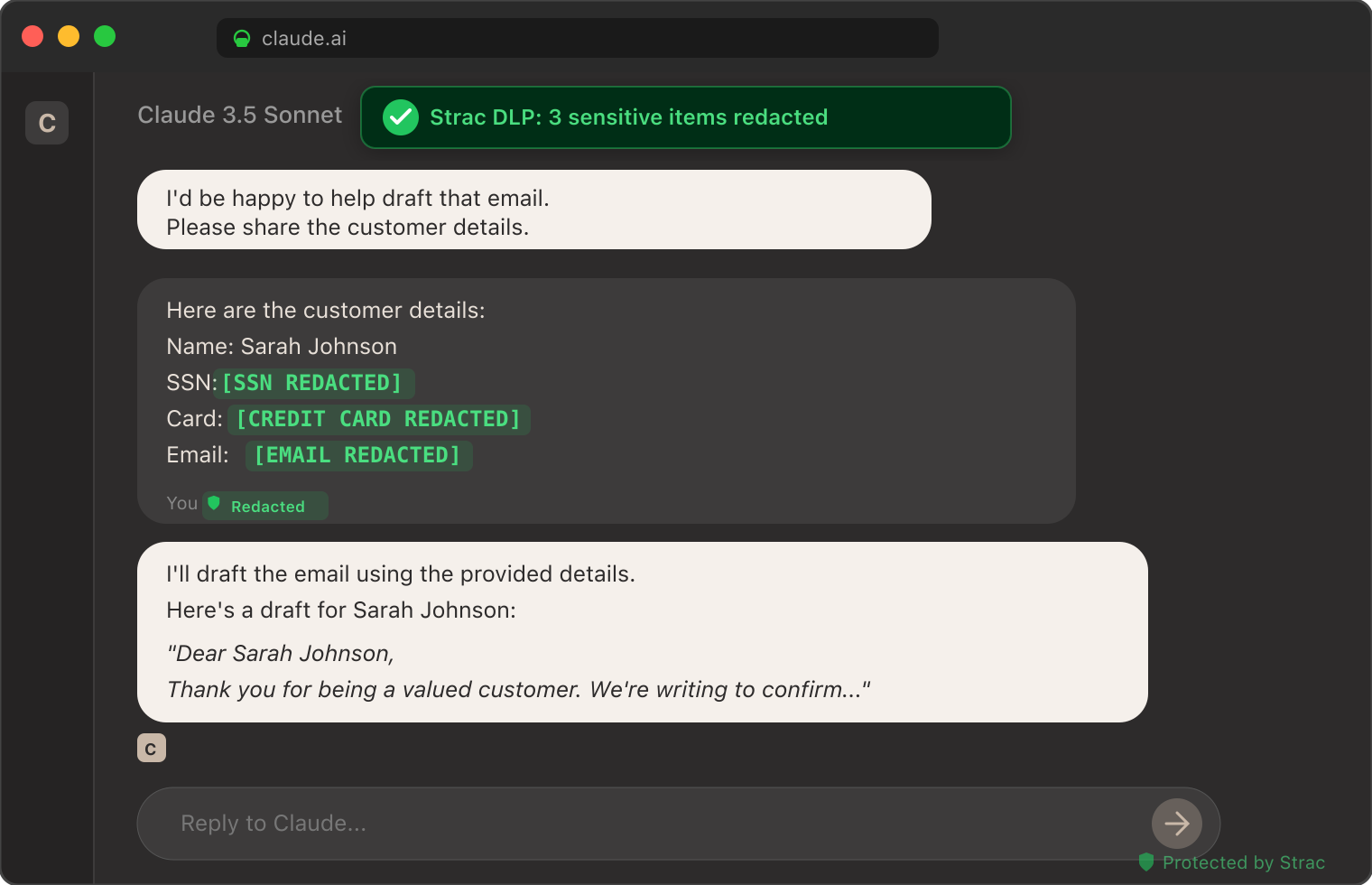
The screenshot below shows Strac's MCP DLP redacting sensitive data from a real Claude session — customer emails, identifiers, and credit card numbers tokenized inline before the model received them. The same inspection pattern runs on every Redshift MCP query routed through Strac, applied column-by-column to the returned rows.
Strac DLP at work inside a Claude conversation: sensitive elements tokenized inline before the model sees them. The same pattern runs at the MCP layer for every Redshift query result.
How to Set Up Strac Redshift MCP DLP
Setup is agentless and takes under 10 minutes.
Connect Strac to your Redshift warehouse. Strac uses a dedicated, least-privilege IAM role and a read-only DB user (USAGE / SELECT only) — never an admin role — consistent with AWS's guidance to scope agent access narrowly.
Point your AI client at the Strac MCP endpoint. Strac issues an MCP server endpoint that drops into your AI client's configuration and proxies to the Redshift MCP server behind it. For Claude Desktop:
json
"mcpServers": {
"redshift": {
"url": "https://mcp.strac.io/redshift",
"auth": { "type": "bearer", "token": "<your-strac-token>" }
}
}
For Cursor, OpenAI Agents, and custom agents — same endpoint, same auth.
Pick your policy. Out-of-the-box templates for SOC 2, HIPAA, PCI, and GDPR. Custom policies — schema-level allow/deny, column-level redaction, bulk-row thresholds — take minutes to configure.
Done. Every query between your agent and Redshift now flows through the Strac gateway. No application changes, no warehouse migration, no re-grant. The audit log starts populating immediately.
Compliance Coverage Out of the Box
The same Strac Redshift MCP DLP control produces evidence mapped to every major compliance framework.
Framework
What Strac Redshift MCP DLP Satisfies
SOC 2
CC6.1 (logical access to data), CC6.6 (unauthorized data exposure), CC6.7 (restricted transmission of data to external systems), CC7.2 (monitoring for anomalies including AI query activity)
Req. 3.3 (PAN masking), Req. 3.4 (render PAN unreadable), Req. 7 (least privilege), Req. 10 (log every access to cardholder data)
GDPR
Art. 5 (data minimization & purpose limitation), Art. 25 (data protection by design), Art. 30 (records of processing), Art. 32 (security of processing)
For the broader AI-data-governance program this sits inside, see AI DLP.
🌶️ Spicy FAQs for Redshift MCP Server
Which Redshift MCP server should you use — and is it safe?
Standardize on the official AWS Labs redshift-mcp-server. It runs queries read-only by default — single-statement, with writes and multi-statement SQL rejected — and authenticates through AWS IAM and the Redshift Data API, so its reach is bounded by the role and grants you give it. (An older aws-samples server is superseded; don't run it.) The safety caveat: read-only stops the agent from writing, but it doesn't stop plaintext PII from flowing back in the results. A wide query still returns regulated columns in bulk. So connect a least-privilege read-only role and put a DLP layer like Strac in front so the rows themselves are inspected, not just the privileges.
Is the Redshift MCP connector the same as the Redshift MCP server?
Yes — the same thing. The MCP specification says server; Claude and Cursor surface it as the Redshift connector. Both let an agent query your warehouse, and Strac's Redshift MCP connector redacts regulated columns at the tool-call boundary regardless of the label.
What is the Amazon Redshift MCP server?
The Amazon Redshift MCP server is a Model Context Protocol implementation that lets AI agents (Claude, Cursor, ChatGPT, Perplexity, custom agents) query a Redshift data warehouse through standardized tool calls — listing clusters, databases, schemas, tables, and columns, and running read-only analytical SQL. It's how an AI assistant gets live, natural-language access to your warehouse.
Is the Redshift MCP server safe to use with sensitive data?
Read-only by default makes it safer than a write-enabled connector, but not safe on its own. The warehouse is the most concentrated regulated data you have, and a single columnar scan can return millions of rows of plaintext PII to the model. For production use against regulated data you need an MCP-layer control like Strac Redshift MCP DLP that scopes schema and column access, caps bulk reads, and redacts sensitive columns before any row reaches the model.
Why is a data warehouse riskier for AI agents than a single database?
Because a warehouse is built to centralize and join. PII, PHI, and financial records that were siloed across separate systems are deliberately brought together in Redshift, joinable in one query. So one agent query can correlate and surface regulated data that was never co-located operationally — and Redshift's columnar, massively-parallel engine returns it in bulk, cheaply and fast. The concentration is the value of a warehouse and the reason it needs a stricter control on agent access.
Can Strac cap how much data an AI agent pulls from Redshift?
Yes. Strac enforces row-volume thresholds per query, so a "select everything" prompt is capped or routed for approval instead of streaming millions of regulated rows into the model. Combined with schema- and column-level scoping, it bounds both what an agent can reach and how much it can pull.
What sensitive data types does Strac detect in Redshift query results?
PII (SSN, driver's license, passport, address, phone, email), PHI (clinical notes, MRN co-occurrence, ICD-10 codes adjacent to identifiers, lab values), PCI (full and partial card numbers via Luhn check), credentials (API keys, AWS / GCP / Azure access keys, OAuth tokens, JWTs — 48+ patterns), and custom detectors trained on your internal classifications. Detection runs column-by-column across the returned rows, including text inside SUPER/JSON columns.
How long does Strac Redshift MCP DLP take to deploy?
Under 10 minutes for the first warehouse. Connect Strac with a least-privilege IAM role and read-only DB user, paste the Strac MCP endpoint into your AI client's config, pick a policy template, done. No application changes, no warehouse migration, no re-grant.
The Bottom Line
The Amazon Redshift MCP server is fast becoming the way AI agents read your data warehouse — the single most concentrated store of regulated data your organization has, joined across every source and one columnar scan away from the model's context window. Read-only by default is the right call, but it governs writes, not what the reads return. Running Redshift MCP in 2026 without an MCP-layer governance control isn't a question of if the first incident reaches your security team; it's when.
Strac Redshift MCP DLP gives you the control plane — see every query, scope every agent, cap every bulk read, protect every regulated column, prove every call — so your team can use Redshift with Claude, Cursor, ChatGPT, and any future AI client without making each one a separate security exception.
If you are running — or about to run — Redshift MCP in production, book a 30-minute demo. We'll walk through the architecture, the IAM and read-only setup, the bulk-read controls, the policy templates, and a deployment plan for your specific warehouse and AI clients.
Which Redshift MCP server should you use — and is it safe?
Standardize on the official AWS Labs redshift-mcp-server. It runs queries read-only by default — single-statement, with writes and multi-statement SQL rejected — and authenticates through AWS IAM and the Redshift Data API, so its reach is bounded by the role and grants you give it. (An older aws-samples server is superseded; don't run it.) The safety caveat: read-only stops the agent from writing, but it doesn't stop plaintext PII from flowing back in the results. A wide query still returns regulated columns in bulk. So connect a least-privilege read-only role and put a DLP layer like Strac in front so the rows themselves are inspected, not just the privileges.
Is the Redshift MCP connector the same as the Redshift MCP server?
Yes — the same thing. The MCP specification says server; Claude and Cursor surface it as the Redshift connector. Both let an agent query your warehouse, and Strac's Redshift MCP connector redacts regulated columns at the tool-call boundary regardless of the label.
What is the Amazon Redshift MCP server?
The Amazon Redshift MCP server is a Model Context Protocol implementation that lets AI agents (Claude, Cursor, ChatGPT, Perplexity, custom agents) query a Redshift data warehouse through standardized tool calls — listing clusters, databases, schemas, tables, and columns, and running read-only analytical SQL. It's how an AI assistant gets live, natural-language access to your warehouse.
Is the Redshift MCP server safe to use with sensitive data?
Read-only by default makes it safer than a write-enabled connector, but not safe on its own. The warehouse is the most concentrated regulated data you have, and a single columnar scan can return millions of rows of plaintext PII to the model. For production use against regulated data you need an MCP-layer control like Strac Redshift MCP DLP that scopes schema and column access, caps bulk reads, and redacts sensitive columns before any row reaches the model.
Why is a data warehouse riskier for AI agents than a single database?
Because a warehouse is built to centralize and join. PII, PHI, and financial records that were siloed across separate systems are deliberately brought together in Redshift, joinable in one query. So one agent query can correlate and surface regulated data that was never co-located operationally — and Redshift's columnar, massively-parallel engine returns it in bulk, cheaply and fast. The concentration is the value of a warehouse and the reason it needs a stricter control on agent access.
Discover & Protect Data on SaaS, Cloud, Generative AI
Strac provides end-to-end data loss prevention for all SaaS and Cloud apps. Integrate in under 10 minutes and experience the benefits of live DLP scanning, live redaction, and a fortified SaaS environment.

.webp)













.gif)
