Atlassian MCP Server: Secure Setup for Claude & AI Agents (2026)
The Atlassian Remote MCP Server connects Jira, Confluence, and Bitbucket to Claude, Cursor, ChatGPT, and AI agents. Here's how it works, the real data-exposure risks across the whole suite, and how Strac governs every tool call with DLP-grade redaction at the MCP layer.
The Atlassian MCP server is one connector for the whole suite: it exposes Jira, Confluence, and Bitbucket to AI agents (Claude, Cursor, ChatGPT, Perplexity, custom agents) over the Model Context Protocol. Atlassian ships its own Remote MCP Server, so one OAuth grant can reach issues, wiki pages, and repositories together.
That suite-wide reach is the point — and the problem. A single Atlassian MCP session can pull a Jira ticket's customer PII, a Confluence runbook's hard-coded credentials, and a Bitbucket repo's secrets in the same conversation. None of it is inspected before it lands in the model's context window.
Strac Atlassian MCP DLP is the governance layer for the whole suite. Strac sits as a gateway on every tool call: it controls what each agent can reach across Jira, Confluence, and Bitbucket (scoped access, allow/block, approval on writes), protects the regulated content in each response (redact, mask, or vault — with OCR on screenshots and HAR files), and logs every call as audit evidence mapped to SOC 2 / HIPAA / PCI / GDPR / EU AI Act / ISO 42001.
Setup is agentless and takes under 10 minutes — one OAuth grant, one MCP endpoint in your AI client, no application code changes and no Atlassian re-permissioning.
What Is the Atlassian MCP Server?
The Atlassian MCP server is a Model Context Protocol implementation that turns the Atlassian Cloud API into a standardized toolset for AI agents. Atlassian publishes its own Atlassian Remote MCP Server, and several community and client-side servers exist as well. Whichever you use, the pattern is the same: an OAuth grant, a connector entry in Claude (or another MCP-aware client), and the server begins answering tool calls.
What makes Atlassian different from a single-app connector is breadth. The same authorization typically spans three very different data stores at once:
Confluence — wiki pages, spaces, runbooks, design docs, meeting notes.
Bitbucket — repositories, pull requests, source files, commit history.
From the user's seat, the agent suddenly understands the team's entire working context — what's broken, why, and where the code lives. From a security seat, an external AI client now has read (and often write) access to three of the most sensitive systems an engineering org runs, through one door. That's exactly why the door needs a control layer.
What AI Agents Can Actually Do With Atlassian MCP
The appeal is that one agent can work across the suite the way a senior engineer does — moving between the ticket, the doc, and the code without context-switching.
Trace an incident end to end. Ask Claude "what happened in the payments outage?" and the agent runs JQL across Jira for the incident tickets, pulls the linked Confluence post-mortem, and opens the Bitbucket PR that shipped the fix — assembling the whole story from three systems in one answer.
Turn a Confluence page into action. It reads a design doc or runbook, then files the Jira tickets to implement it — copying acceptance criteria straight out of the wiki into issue descriptions.
Summarize a sprint with the code context. The agent rolls up issue statuses from Jira and cross-references the merged pull requests in Bitbucket, so the standup digest reflects what actually shipped, not just what was marked done.
Read everything attached. It opens issue comment threads, the screenshots and HAR captures hanging off them, and the exported logs a teammate dropped into a Confluence page while debugging.
Write back across the suite. From a Slack thread or meeting note, the agent creates Jira issues, transitions their status, edits a Confluence page, or comments on a Bitbucket PR — real writes into all three systems.
That cross-system reach — a JQL pull here, a wiki read there, a repo fetch alongside it — is precisely why each agent's access has to be scoped, the content it pulls back inspected, and every call recorded before any of it reaches the model.
The Real Security Risks of the Atlassian MCP Server
Because one grant spans three data stores, the exposure surface is wider than any single-app MCP server. Five risks every healthcare, fintech, and enterprise security team should price in:
1. Jira issues carry regulated data in customer and incident tickets. Issue bodies routinely contain customer PII pasted as bug context, stack traces with PHI or PCI, pasted API keys, and exported logs with credentials — all returned in full by a single jql_search or get_issue call.
2. Confluence is a credential and IP graveyard. Runbooks, onboarding pages, and "temporary" setup docs are full of hard-coded passwords, connection strings, API tokens, and architecture detail that never gets cleaned up. One get_page can return all of it.
3. Bitbucket exposes source code and secrets. Repository reads and PR diffs surface proprietary source, .env files, private keys, and tokens committed by mistake — the highest-value data an attacker (or an over-permissioned agent) can reach.
4. Attachments hide secrets inside images and HAR files. Across Jira and Confluence, attachments include screenshots and HAR captures — both notorious for leaking auth headers and secrets that only OCR-inside-image and HAR-aware inspection will catch.
5. One session crosses all three. The real danger of a suite-wide connector is correlation: an agent can join a customer identifier in a Jira ticket to a credential in a Confluence doc to a code path in Bitbucket — assembling something far more sensitive than any single record.
The DLP a company already runs — at the network edge, on the file share, inside each app's native rule engine — does not sit in the MCP path. The tool response goes straight from Atlassian into the AI agent's context window. That gap is where Strac Atlassian MCP DLP lives. It's the same shift we describe in MCP DLP: data protection has moved from egress to ingress — what agents pull in.
Strac's Atlassian MCP DLP is the governance gateway between AI agents and the Atlassian MCP server, and it intercepts every tool call across the whole suite on four fronts. You see every call each agent makes into Jira, Confluence, and Bitbucket. You control what each agent can reach and do — scoping access per agent and per product, with allow/block plus approval on high-risk actions like ticket writes, page edits, and repo access. You protect the regulated content in each response — sensitive data is redacted, tokenized, or vaulted by policy while everything else flows through untouched. And you prove it, because every call is logged as audit evidence.
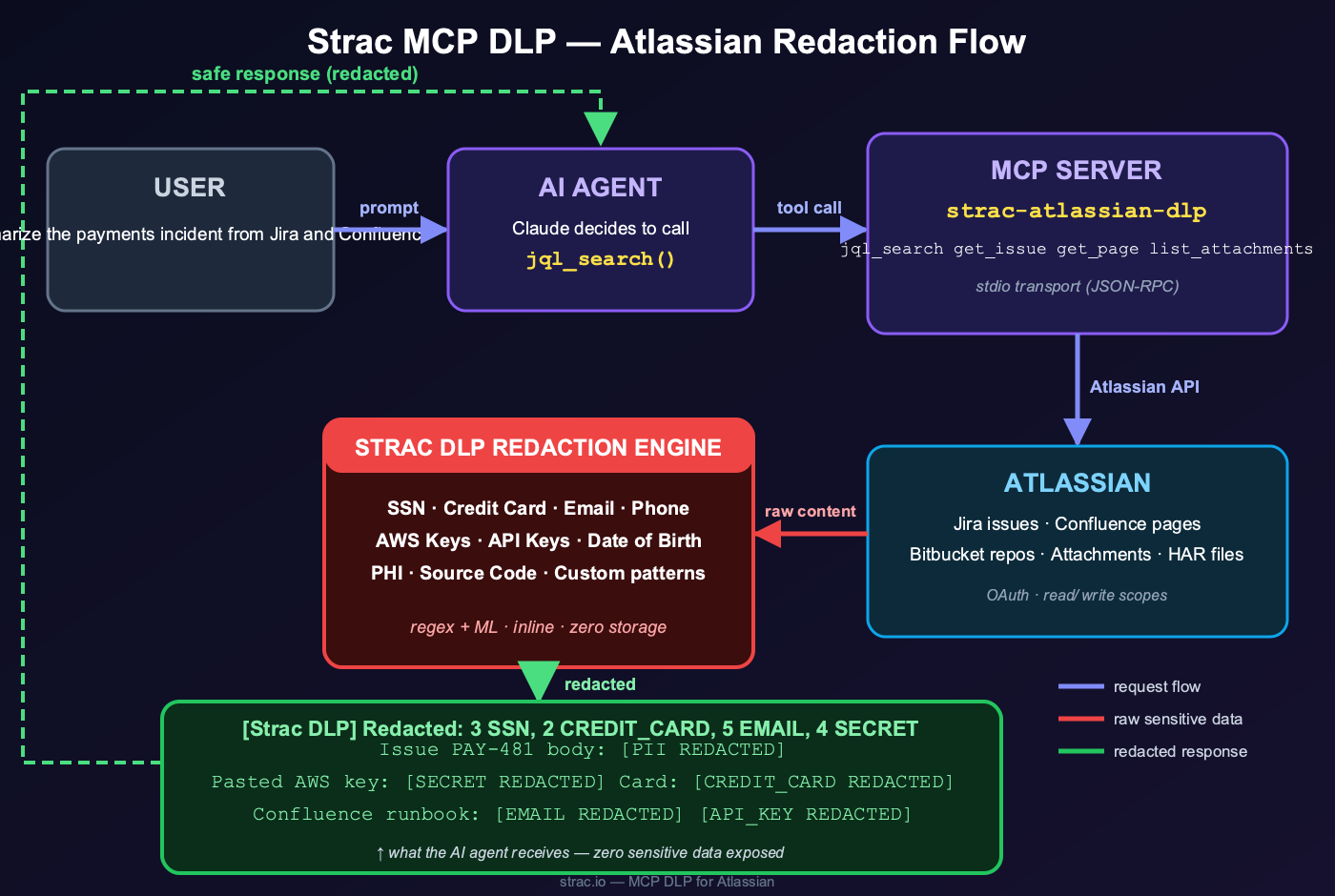
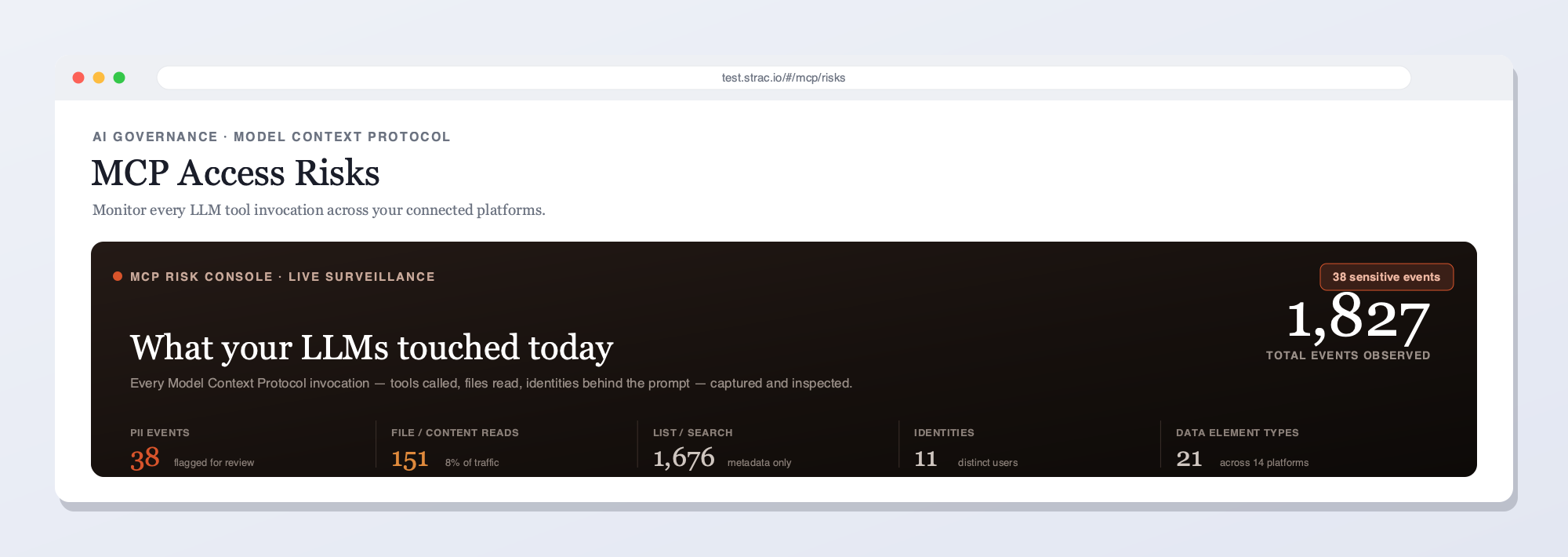
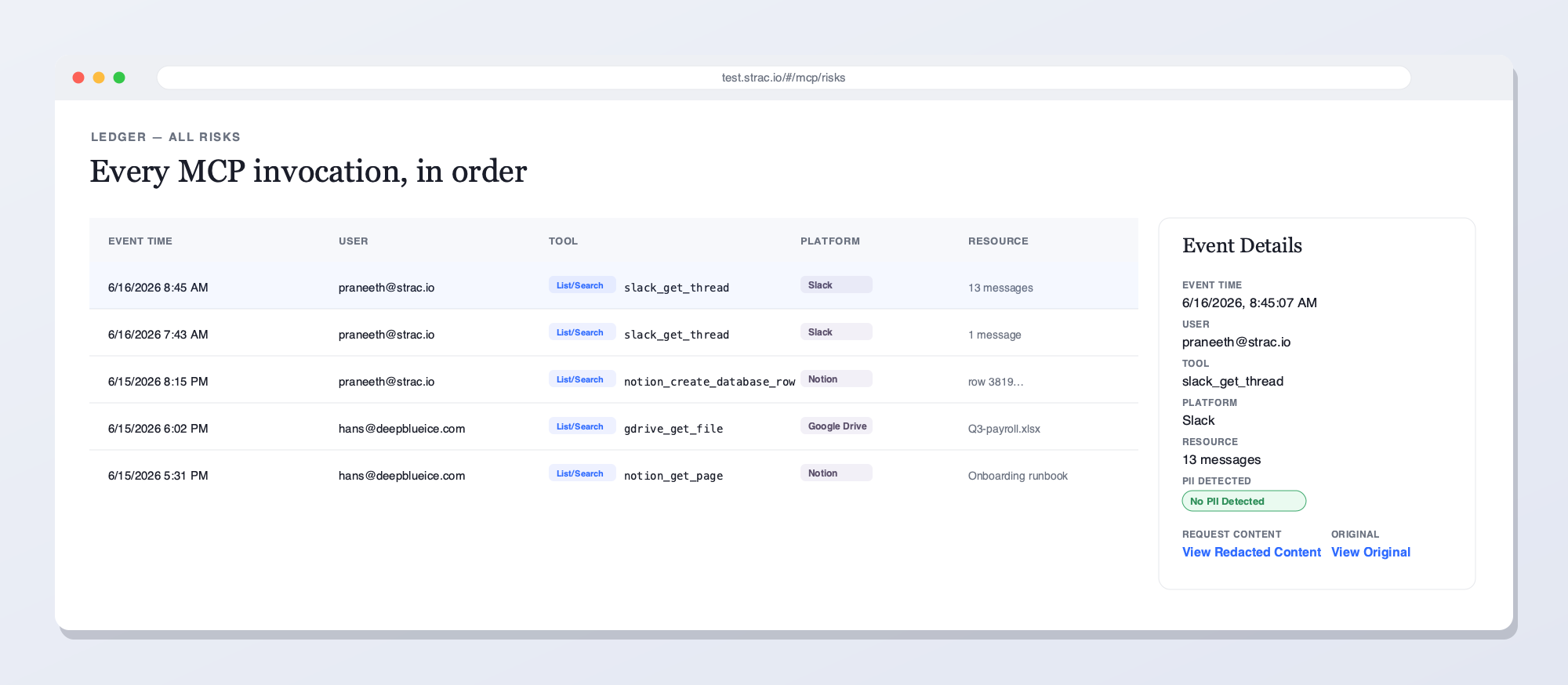
The Strac Atlassian MCP DLP gateway intercepts every tool call between any AI agent (Claude, Cursor, ChatGPT, custom) and the Atlassian MCP server. PII, PHI, PCI, secrets, source code, and content inside images and HAR files are redacted before the agent ever reads them — across Jira, Confluence, and Bitbucket.The full data flow: a prompt triggers a tool call, the MCP server fetches from Jira / Confluence / Bitbucket, and Strac strips SSNs, cards, emails, PHI, secrets, and source code before the redacted response reaches the model.Strac's live MCP Access console — every AI agent tool call touching Atlassian and your other connected platforms, captured and inspected for sensitive data in real time. See what your LLMs reached for, who prompted, and what was flagged.Every MCP invocation in order — user, tool, platform, and the sensitive data found — with redacted vs. original content and a full audit trail. This is what Strac shows on Atlassian that access-only gateways can't: the data in each call, not just the call.
Strac vs. access-only MCP gateways
A gateway that only governs access can tell you an agent called a Atlassian tool — but not that the secrets in a Confluence page or the PII in a Jira ticket came back in the response. Strac inspects the content of every call, remediates the sensitive data — redact, mask, block, or delete — before the model sees it, and still logs the full access trail. You get access control and the data layer, in one place.
What Strac does on every Atlassian tool call
One inline pass over each MCP response — five actions, enforced by your policy:
Detect — finds secrets in a Confluence page or PII in a Jira ticket and any PII, PHI, PCI, secrets, or source code in the payload, including text inside images via OCR.
Redact or mask — replaces the sensitive elements inline, so the agent still gets its answer and the model never sees the raw data.
Block or require approval — stops a high-risk action like a write across Jira, Confluence, or Bitbucket, or routes it for sign-off before it runs.
Alert — notifies your team and streams the event to your SIEM (Datadog, Splunk, Chronicle) in real time.
Audit — logs who, which agent, which tool, what data, and the action taken — evidence mapped to SOC 2, HIPAA, GDPR, and ISO 42001.
What this looks like in practice:
Read tools are filtered. On any read across the suite, Strac inspects the payload, redacts SSNs / cards / emails / PHI / API keys / secrets / source code inline, and passes the clean result to the agent. The agent still does its job; the regulated data never enters the model context.
Write tools are guardrailed. When an agent creates a Jira issue, edits a Confluence page, or comments on a Bitbucket PR with sensitive content, Strac redacts, vaults, or blocks the outgoing payload based on policy.
Files, attachments, images, and HAR captures are inspected at depth. PDFs, DOCX, XLSX, ZIPs, screenshots, and HAR files run through the same OCR and document-parser pipeline Strac uses across its data security product line.
Per-product policy. Different rules for Jira vs Confluence vs Bitbucket — Strac maps to your existing data classification, not an MCP-specific silo.
Every invocation is logged. AI client, user, product, tool name, resource, data classes detected, redactions applied, disposition — the SOC 2 / HIPAA / PCI / GDPR evidence, produced automatically.
🎥 Strac Native Atlassian DLP — The Companion to MCP DLP
MCP DLP protects the AI-agent surface. Strac's native Atlassian DLP protects the direct-user surface — the same Jira and Confluence, inspected where humans paste, upload, and share. Most enterprises run both: native DLP for user-driven actions, MCP DLP for agent-driven actions. Together they cover every path regulated data takes in and out of Atlassian.
What Strac's native Atlassian DLP includes:
Continuous discovery and classification of PII, PHI, PCI, credentials, and source-code secrets across Jira issues, Confluence pages, and Bitbucket repos
Inspection of pasted production data: stack traces with PHI/PCI, exported logs with credentials, screenshots with secrets
Custom-field and wiki-macro scanning, where regulated data routinely hides
Attachment inspection at depth: PDFs, HAR files (notorious for auth-header leaks), DOCX, XLSX, and image attachments via OCR
Automatic redaction or vault-redaction so the ticket or page stays useful while the regulated data is contained
Audit logs mapped per finding to SOC 2 CC6, HIPAA Security Rule, PCI DSS, and GDPR
For the broader catalog — every SaaS, cloud, browser, and endpoint surface Strac covers across SaaS, cloud, GenAI, browser, and endpoints — see strac.io/integrations.
Two asks come up across an Atlassian rollout. You define the enforcement — mask, redact, or run a custom regex across Jira and Confluence content — through one managed classifier rather than a self-managed Presidio or Bedrock pipeline. And the protection extends to the custom tools your team builds on Atlassian data for employees and customers, beyond the packaged connector.
✨ See Strac MCP DLP in Action
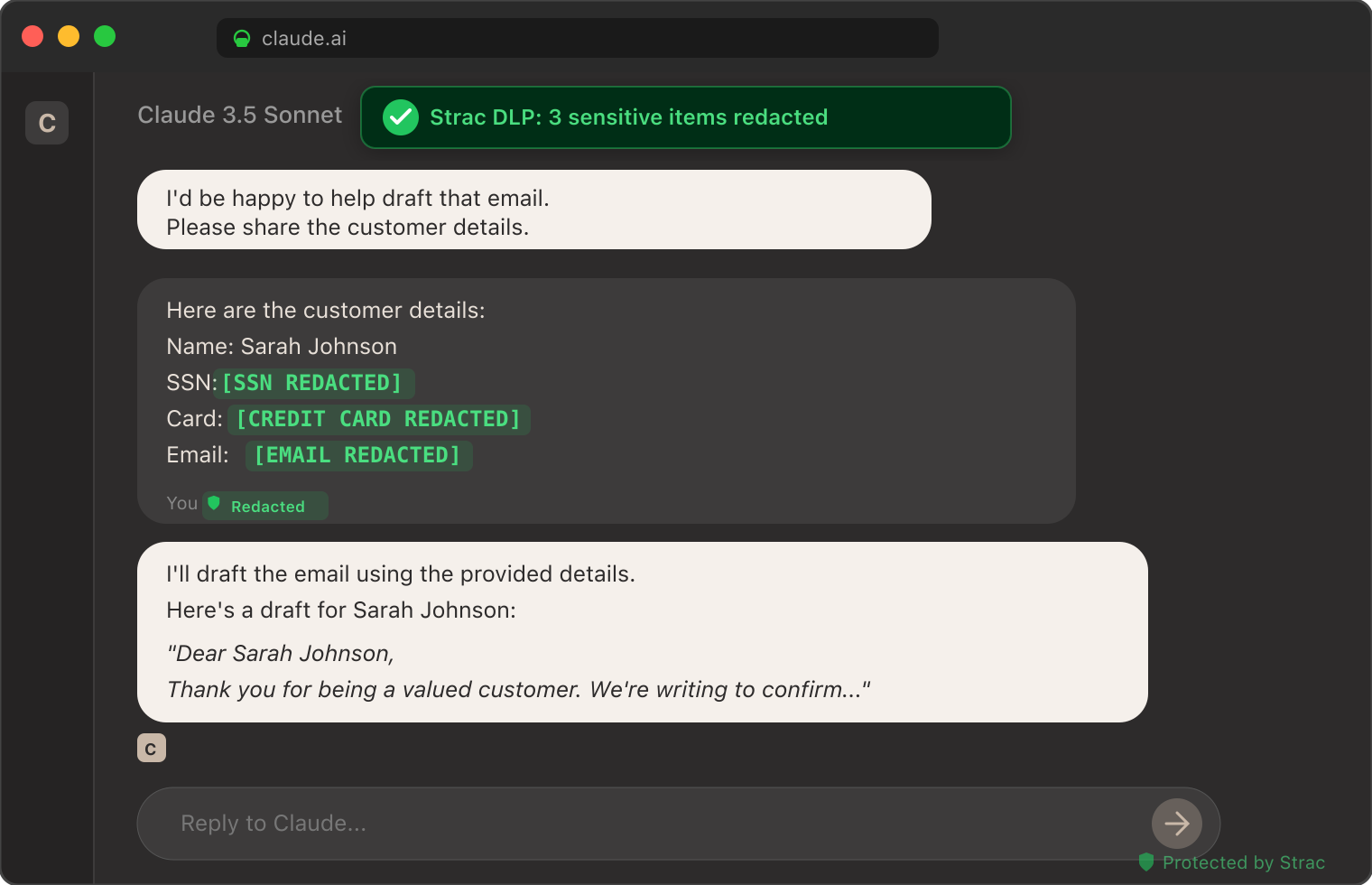
The screenshot below shows Strac's MCP DLP redacting sensitive data from a real Claude session — patient identifiers, customer emails, and credit card numbers tokenized inline before the model received the prompt. The same inspection runs on every Atlassian MCP tool call routed through Strac, whether it came from Jira, Confluence, or Bitbucket.
Strac DLP inside a Claude conversation: sensitive elements tokenized inline before the model sees them. The same pattern runs at the MCP layer for every Atlassian tool call. See [Claude DLP](https://www.strac.io/blog/claude-dlp) and [GenAI DLP](https://www.strac.io/blog/ai-dlp).
How to Set Up Strac Atlassian MCP DLP
Setup is agentless and takes under 10 minutes.
Authorize Strac with your Atlassian Cloud tenant via OAuth. Strac requests the read/write scopes for the products you want covered — Jira, Confluence, Bitbucket, or all three. It honors Atlassian's permission model: Strac only sees what the authorizing user or bot can see.
Configure the MCP gateway endpoint. Strac issues an MCP server endpoint that drops into your AI client's MCP configuration. For Claude Desktop:
json
"mcpServers": {
"atlassian": {
"url": "https://mcp.strac.io/atlassian",
"auth": { "type": "bearer", "token": "<your-strac-token>" }
}
}
For Cursor, OpenAI Agents, and custom agents — same endpoint, same auth.
Pick your policy. Out-of-the-box templates for SOC 2, HIPAA, PCI, and GDPR, with per-product overrides for Jira, Confluence, and Bitbucket. Custom policies (resource-level, data-class-level, action-level) take minutes.
Done. Every Atlassian MCP tool call between your agent and the suite now flows through Strac. No application code changes, no agent code changes. The audit log starts populating immediately.
Compliance Coverage Out of the Box
The same Strac Atlassian MCP DLP control produces evidence mapped to every major framework — the enforce-and-prove combination most tools miss.
Framework
What Strac Atlassian MCP DLP Satisfies
SOC 2
CC6.6 (unauthorized data exposure), CC6.7 (restricted transmission to external systems), CC7.2 (monitoring for anomalies including AI usage)
The Atlassian MCP server is a Model Context Protocol implementation that lets AI agents (Claude, Cursor, ChatGPT, Perplexity, custom agents) read and act inside Jira, Confluence, and Bitbucket via standardized tool calls. Atlassian ships its own Remote MCP Server; one OAuth grant can span all three products.
Does the Atlassian MCP server cover Jira, Confluence, and Bitbucket together?
Yes — that's the difference from a single-app connector. One authorization typically spans the whole suite: Jira issues and comments, Confluence pages and spaces, and Bitbucket repositories and pull requests. It's convenient, and it's exactly why a suite-wide DLP layer matters: an agent can correlate a customer ID in Jira with a credential in Confluence and a code path in Bitbucket in a single session. Strac applies per-product policy so each store is governed to its own sensitivity.
Atlassian MCP vs Atlassian Rovo — what's the difference?
They approach "AI in your Atlassian data" from opposite directions. Rovo is Atlassian's own AI, built natively inside the platform — the agents and chat that ship with Jira and Confluence. The Atlassian MCP server is the reverse: an external agent — Claude, Cursor, a custom assistant — reaches into Atlassian over MCP to read and write. The deciding question is where the intelligence sits: inside Atlassian's walls (Rovo) or in a client you bring (MCP). That external hand-off — data leaving Atlassian for an outside client — is precisely where Strac MCP DLP inspects the response and redacts anything sensitive first.
Is the Atlassian MCP server safe to use with sensitive data?
By itself, no — not without an added DLP layer. The Atlassian MCP server honors the authorizing user's permissions but returns whatever that user can see, including PII, PHI, credentials, and source code across three products. For enterprise use with regulated data you need an MCP-layer control like Strac Atlassian MCP DLP that inspects and redacts every tool response before content reaches the model.
Does Strac Atlassian MCP DLP work with Claude, ChatGPT, Gemini, Copilot, and Perplexity?
Yes. Strac exposes a standard MCP gateway endpoint, so any MCP-aware AI client — Claude and Claude Code, Cursor, ChatGPT, Gemini, Microsoft Copilot, Perplexity, or a custom agent — routes its Atlassian tool calls through Strac with one configuration change. No SDK changes, no application code changes. Note that not every client supports remote MCP servers identically; Strac works with whichever transport your client uses.
What sensitive data types does Strac detect in Atlassian MCP tool responses?
PII (SSN, driver's license, passport, address, phone, email), PHI (clinical notes, MRN co-occurrence, ICD-10 codes adjacent to identifiers, lab values), PCI (full and partial card numbers via Luhn check), credentials (API keys, AWS / GCP / Azure access keys, OAuth tokens, JWTs, SSH and private keys — 48+ patterns), proprietary content (source-code fingerprints, M&A keywords), and custom detectors trained on your data classifications. Detection runs across text, files, images (OCR), HAR captures, and structured fields.
How long does Strac Atlassian MCP DLP take to deploy?
Under 10 minutes for the first tenant. OAuth Strac into Atlassian, paste the Strac MCP endpoint into your AI client, pick a policy template, done. No agents to install, no Atlassian re-permissioning, no application code changes.
Can I see what an AI agent did across Jira, Confluence, and Bitbucket?
Yes. Strac produces a per-call audit log: timestamp, AI client identity, user, product, tool invoked, resource accessed, data classes detected, redactions applied, vault references, disposition. It's queryable in the Strac console and exportable to your SIEM — the evidence trail SOC 2, HIPAA, PCI, and GDPR auditors will ask about for AI-agent activity in Atlassian.
The Atlassian MCP server is a Model Context Protocol implementation that lets AI agents (Claude, Cursor, ChatGPT, Perplexity, custom agents) read and act inside Jira, Confluence, and Bitbucket via standardized tool calls. Atlassian ships its own Remote MCP Server; one OAuth grant can span all three products.
Does the Atlassian MCP server cover Jira, Confluence, and Bitbucket together?
Yes — that's the difference from a single-app connector. One authorization typically spans the whole suite: Jira issues and comments, Confluence pages and spaces, and Bitbucket repositories and pull requests. It's convenient, and it's exactly why a suite-wide DLP layer matters: an agent can correlate a customer ID in Jira with a credential in Confluence and a code path in Bitbucket in a single session. Strac applies per-product policy so each store is governed to its own sensitivity.
Atlassian MCP vs Atlassian Rovo — what's the difference?
They approach "AI in your Atlassian data" from opposite directions. Rovo is Atlassian's own AI, built natively inside the platform — the agents and chat that ship with Jira and Confluence. The Atlassian MCP server is the reverse: an external agent — Claude, Cursor, a custom assistant — reaches into Atlassian over MCP to read and write. The deciding question is where the intelligence sits: inside Atlassian's walls (Rovo) or in a client you bring (MCP). That external hand-off — data leaving Atlassian for an outside client — is precisely where Strac MCP DLP inspects the response and redacts anything sensitive first.
Is the Atlassian MCP server safe to use with sensitive data?
By itself, no — not without an added DLP layer. The Atlassian MCP server honors the authorizing user's permissions but returns whatever that user can see, including PII, PHI, credentials, and source code across three products. For enterprise use with regulated data you need an MCP-layer control like Strac Atlassian MCP DLP that inspects and redacts every tool response before content reaches the model.
Does Strac Atlassian MCP DLP work with Claude, ChatGPT, Gemini, Copilot, and Perplexity?
Yes. Strac exposes a standard MCP gateway endpoint, so any MCP-aware AI client — Claude and Claude Code, Cursor, ChatGPT, Gemini, Microsoft Copilot, Perplexity, or a custom agent — routes its Atlassian tool calls through Strac with one configuration change. No SDK changes, no application code changes. Note that not every client supports remote MCP servers identically; Strac works with whichever transport your client uses.
Discover & Protect Data on SaaS, Cloud, Generative AI
Strac provides end-to-end data loss prevention for all SaaS and Cloud apps. Integrate in under 10 minutes and experience the benefits of live DLP scanning, live redaction, and a fortified SaaS environment.

.webp)














.gif)
