AI Data Governance: Framework, Best Practices & How to Implement It (2026)
AI data governance is how enterprises control the data flowing into, through, and out of AI systems. Learn the framework, the regulations, and a 90-day implementation playbook.
AI data governance is the discipline of controlling the data that flows into, through, and out of AI systems — training data, prompts, retrieved context, outputs, fine-tuning sets, and agent memory. It is not the same as AI governance, which is about controlling models (bias, accuracy, ethics, ops).
Most enterprise risk in 2026 lives at the data layer, not the model layer. Customer PII pasted into ChatGPT, source code uploaded to Copilot, contracts indexed by Notion AI, OAuth grants giving AI vendors full Drive access — these are data governance failures, not model governance failures.
The regulatory stack is now real: EU AI Act (data governance is Article 10), NIST AI RMF (Map–Measure–Manage–Govern, all four wired through data), ISO/IEC 42001 (AI management system, data lifecycle is core), SOC 2 CC6, GDPR Articles 5, 25, 35, and a growing list of state laws (Texas TDPSA, Colorado AI Act, California CPRA AI rules).
A working AI data governance framework has five pillars: discovery and classification, access and identity, in-flight data protection, audit and accountability, and vendor/model lifecycle. Each pillar maps to specific clauses in NIST AI RMF, ISO 42001, EU AI Act, and SOC 2.
The 90-day implementation pattern that works: weeks 1–3 inventory every AI tool and data flow, weeks 4–7 deploy data classification and prompt-level redaction, weeks 8–12 wire audit, vendor reviews, and continuous monitoring into the existing GRC program.
What is AI Data Governance?
AI data governance is the set of policies, controls, and tooling that determines what data is allowed to be used by AI systems, how that data is protected at every stage of the AI lifecycle, and who is accountable when something goes wrong.
It answers questions like:
Is this dataset clean enough to use as AI training data?
Can a customer support agent paste a customer's chat transcript into ChatGPT?
Should this AI vendor be allowed read access to our Google Drive?
When the model produces an output containing PII, what happens?
Who owns the audit trail when an AI agent takes action on data?
AI data governance sits at the intersection of three older disciplines: data governance (data quality, lineage, ownership), data security (classification, access control, redaction), and AI governance (model accountability, bias, transparency). The growth of generative AI made this intersection load-bearing — because for the first time, sensitive data is being shipped, in real time, to systems that none of those three disciplines were designed to handle on their own.
AI Data Governance vs. AI Governance — they are not the same
This distinction matters and it shows up in audits.
AI Governance
AI Data Governance
Object of control
The model
The data
Typical questions
Is the model accurate? Biased? Explainable? Auditable?
What data went in? Was it allowed to? Who can see the output? Where did it leak?
Owners
ML/AI engineering, ethics committee, model risk
Security, privacy, data governance, compliance
Frameworks
NIST AI RMF (Manage), ISO 42001 (model lifecycle), EU AI Act (high-risk model classes)
NIST AI RMF (Map–Measure for data), ISO 42001 §6.1.4, EU AI Act Article 10, SOC 2 CC6, GDPR
Failure mode
A model produces unfair outputs
A model is fed (or produces) data it should never have touched
In practice, every enterprise needs both. But for any company that consumes AI rather than builds it — which is the vast majority — AI data governance is the bigger lever. You can't fix model bias in a vendor's foundation model, but you absolutely control whether your customer PII ever reaches that model.
✨ Why AI Data Governance Matters Now (And Why It's Different from 2022)
For most of the last decade, "data governance for AI" meant a handful of data engineers worrying about training-set quality for an internal ML model. That world is gone.
Three things changed:
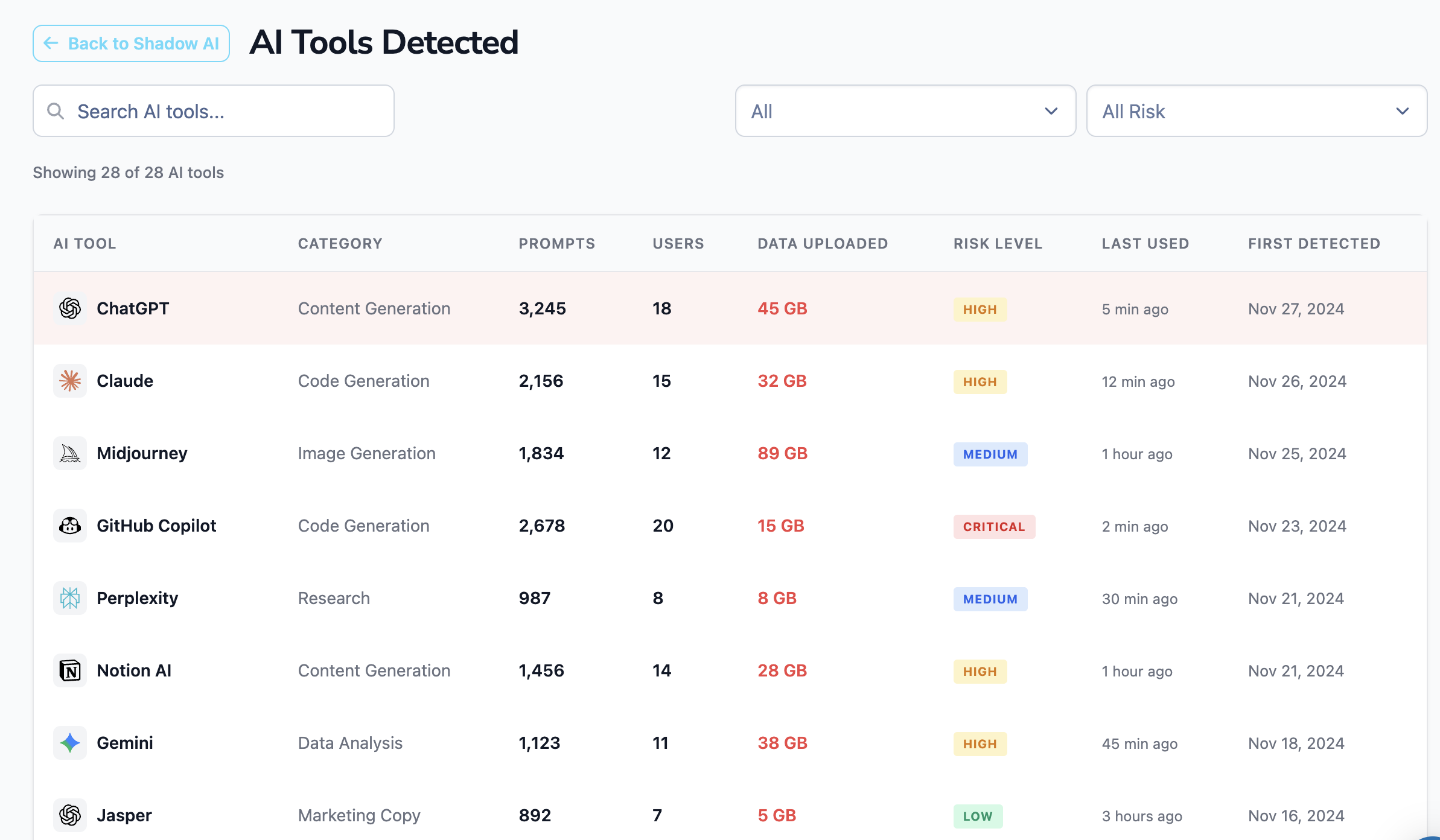
1. The data surface exploded. Every employee with a browser is now a potential data exporter. The average mid-market company has 25–30 AI tools in active use across the workforce. Most of those tools were never reviewed by security, never signed a DPA, and never appeared on an asset inventory. (See Shadow AI: Definition, Risks, and How to Detect It for the full discovery problem.)
An AI data governance dashboard surfaces every AI tool in use, every prompt, every byte uploaded, and the users with the highest data exposure — the foundation of any governance program.
2. The regulators caught up. In 2022, "AI data governance" was a phrase you only heard at academic conferences. In 2026 it appears, by name or by clause, in:
EU AI Act, Article 10 — explicit data governance obligations for high-risk AI systems
NIST AI Risk Management Framework — the Map and Measure functions are entirely about data
ISO/IEC 42001:2023 — clauses 6.1.4, 7.4, and 8.4 cover data lifecycle in AI management systems
SOC 2 Common Criteria 6.1, 6.6, 6.7 — interpreted to cover AI-bound data flows
GDPR — Articles 5 (purpose limitation), 25 (privacy by design), and 35 (DPIAs) apply directly to AI processing
Texas TDPSA, Colorado AI Act, California CPRA — automated decision-making and AI-specific obligations
HIPAA — OCR's 2024–2025 guidance on AI assistants in clinical workflows
NYDFS Part 500 amendment — covered entities must inventory AI tools and assess data exposure
3. The business consequence got real. Samsung banned ChatGPT after engineers pasted source code into it. JPMorgan blocked it firm-wide for the same reason. Air Canada was held legally bound by its chatbot's hallucination. The DPC fined Italian DPAs over OpenAI's training data sourcing. Every one of these is a data governance failure, not a model governance failure.
✨ The 5 Pillars of an AI Data Governance Framework
Every credible AI data governance framework — whether you're mapping to NIST AI RMF, ISO 42001, EU AI Act, or your own internal program — reduces to five operational pillars. Use them as the spine of your policy and your tooling.
1. Discovery and Classification
You cannot govern data you do not know exists, and you cannot make policy decisions about data you have not classified.
What this means in practice:
A continuously updated inventory of every AI tool, agent, model endpoint, and AI-enabled SaaS feature in use across the organization — sanctioned and unsanctioned alike.
A data classification program that distinguishes regulated data (PII, PHI, PCI, financial), proprietary data (source code, M&A docs, customer lists, contracts), and public/non-sensitive data, at the file, record, prompt, and field level.
Lineage from origin (Salesforce record, Drive doc, Slack message) through every system it touches, including AI tools.
Data flow maps for high-risk AI use cases (customer support, code generation, marketing, internal search), so DPIAs and risk assessments have something concrete to reference.
The first pillar is also the one most programs underinvest in. A classification model trained on file shares from 2019 will not catch a screenshot of a credit card pasted into a ChatGPT prompt in 2026. AI data governance requires classification at the moment of use, not at rest in a data lake.
2. Access and Identity
Once you know what data exists and where AI lives, you need to control who and what can connect them.
What this means in practice:
Identity-aware policies: an L1 support rep does not need write access to an LLM with the production database in its retrieval scope.
OAuth and API token governance: every AI tool that connects to Google Drive, Slack, Salesforce, or GitHub via OAuth is a third-party data processor. Inventory those grants. Most enterprises have hundreds; most have reviewed zero.
SSO + SCIM enforcement for AI tools, so a departing employee actually loses AI access.
Just-in-time access for high-sensitivity AI workloads — engineers fine-tuning a model on customer data should not have standing access to that data after the run.
Role-based scoping for AI agents: an MCP server running with the user's full filesystem privilege is a governance violation, not a feature.
3. In-Flight Data Protection
Discovery and access controls reduce the surface. They do not stop the moment a sales rep pastes a customer's full account export into ChatGPT to "summarize the relationship." For that you need controls in the data path itself.
What this means in practice:
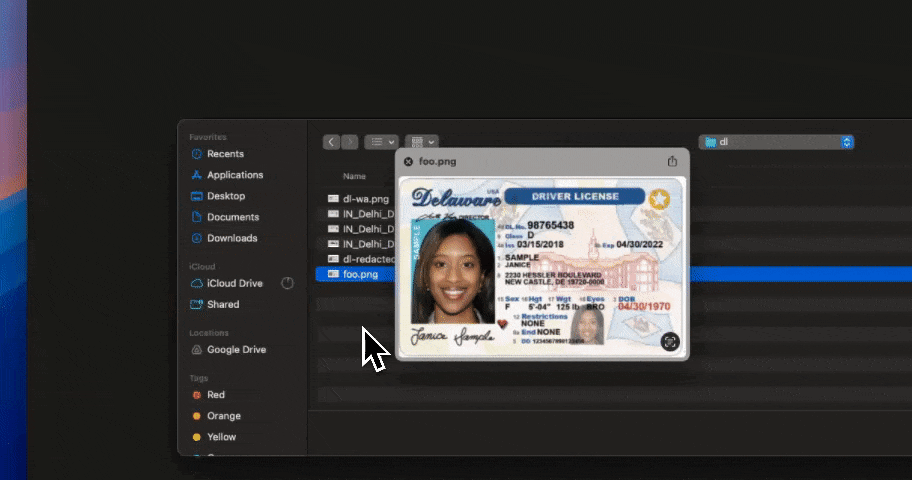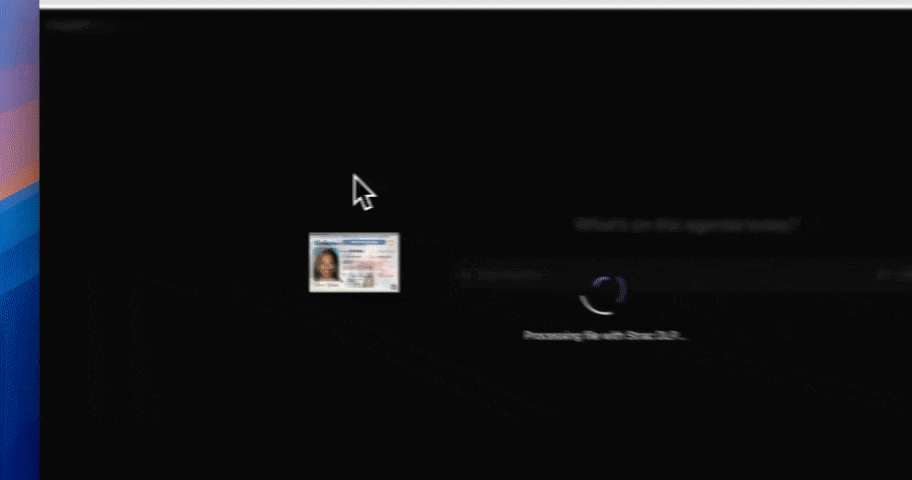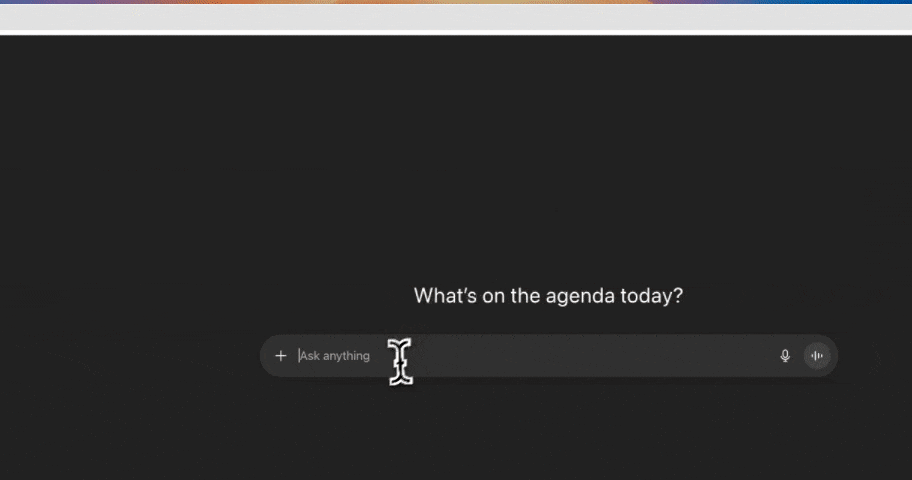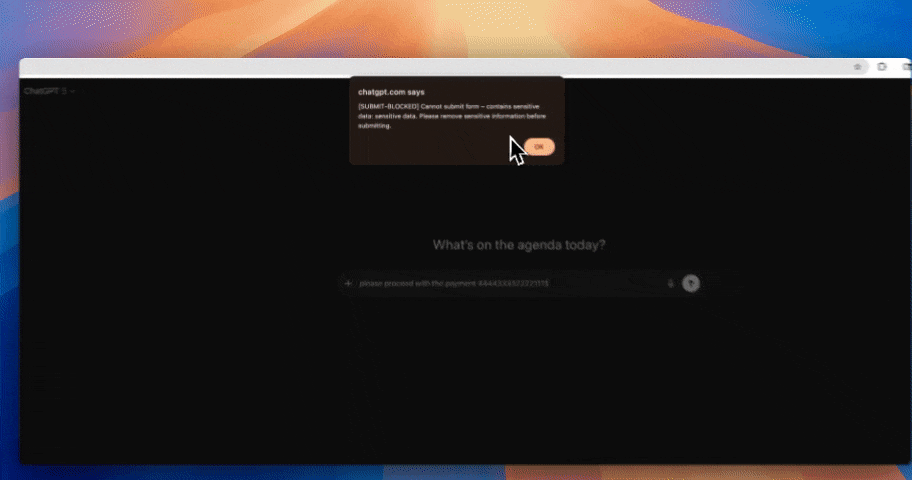
Prompt-level redaction: regulated and proprietary data is stripped or tokenized before it reaches the model.
Output filtering: the model's response is scanned before it returns to the user, so a hallucinated SSN or a leaked record from a poisoned context window is blocked.
File and document inspection: PDFs, spreadsheets, screenshots, and ZIPs uploaded to AI tools are inspected for sensitive content — including text inside images, which is where most modern data security tools fail.
Browser, endpoint, and SaaS coverage: redaction has to work where employees actually work, not just where the IT team has agents installed.
In-flight data protection is the difference between a policy and a control. Strac inspects the prompt as the user types, redacts regulated and proprietary content, and only then lets it reach the model.
4. Audit, Logging, and Accountability
When auditors, regulators, or your board ask "what data did this AI system see, and on whose behalf?" you need an answer in minutes, not weeks.
What this means in practice:
A unified audit log of every AI interaction: tool, user, timestamp, prompt fingerprint, data sensitivity, redactions applied, output disposition.
Findings tied to identifiable users and tickets, not anonymous SIEM alerts that no one closes.
Integration with the GRC program: an AI data governance violation should generate evidence inside the same control framework that handles SOC 2 and ISO 27001.
Defensible logs of consent, purpose, and lawful basis for every regulated data category processed by AI — this is where GDPR Article 30 and HIPAA accounting-of-disclosures requirements land.
A defensible AI data governance audit starts with an inventory like this — every AI tool, every user, every byte uploaded, with first-detected and last-used timestamps an auditor can verify.
5. Vendor and Model Lifecycle Governance
Most AI in your enterprise is third-party AI. Governance has to extend to the vendor.
What this means in practice:
Pre-procurement due diligence: data residency, training-data use opt-outs, retention, sub-processors, model versioning, breach notification, EU AI Act conformity.
Contractual clauses: Data Processing Addenda (DPAs), AI-specific schedules, source-data-rights warranties, indemnification for IP and privacy claims.
Continuous monitoring: vendors change their privacy posture without telling you. The OpenAI training-data toggle, Microsoft Copilot's tenant-isolation guarantees, Google's enterprise data terms — all have moved in the last 18 months.
Decommissioning playbooks: when a tool is removed, its OAuth grants must be revoked, its API keys rotated, its retained data confirmed deleted, and its evidence trail preserved for the audit window.
How AI Data Governance Maps to Every Major Framework
If you are building a program, you do not get to pick one framework. You will be assessed against several. The good news: a single, well-designed AI data governance program satisfies most of them with the same controls.
NIST AI Risk Management Framework (AI RMF 1.0)
NIST AI RMF organizes work into four functions: Govern, Map, Measure, Manage. Data governance lives mostly in Map (context and data sources) and Measure (testing and monitoring).
Map 1, 2, 3 — inventory of AI systems, data sources, intended use, and known risks.
Map 4 — third-party (vendor) considerations.
Measure 2.7, 2.8, 2.9 — privacy, security, and integrity of data and the ML pipeline.
Manage 4.1 — post-deployment monitoring of data drift and risk.
Your five-pillar program covers all four functions if you wire it correctly: pillar 1 satisfies Map, pillars 2 and 3 satisfy Manage, pillar 4 satisfies Measure, and pillar 5 satisfies the third-party clauses.
ISO/IEC 42001:2023 — AI Management System
ISO 42001 is the first international standard for an AI management system. It treats AI like ISO 27001 treats information security — as a managed, audited, continuously improved program.
Clause 6.1.4 — risk treatment for AI systems.
Clause 7.4 — communication, including with data subjects.
Clause 8.4 — operational controls over the AI lifecycle, explicitly including data.
Annex A.7 — data for AI systems (provenance, quality, preparation).
Annex A.8 — information for interested parties.
For an organization already certified to ISO 27001, layering 42001 is mostly an exercise in extending the existing ISMS. The data-governance pillars sit naturally inside the existing risk register.
EU AI Act
The EU AI Act takes effect on a staggered schedule through 2027. The data governance obligations live in Article 10 for high-risk AI systems and have direct extra-territorial impact: any AI system whose output is used in the EU is in scope, regardless of where it is built.
Article 10 requires:
Training, validation, and test data to meet quality criteria.
Data governance and management practices including provenance, preparation, bias examination, and gap identification.
Documentation sufficient to demonstrate compliance to a notified body or supervisory authority.
For most enterprises, the practical impact is the transparency and documentation burden — you must be able to show a regulator the lineage of every dataset that touches a high-risk system. Pillar 1 (discovery) and pillar 4 (audit) carry most of this weight.
SOC 2 Common Criteria
SOC 2 does not (yet) have an "AI" trust services criterion, but auditors are increasingly applying the existing CC6 (logical and physical access) and CC7 (system operations) clauses to AI-bound data flows.
CC6.1 — access controls, including AI tool access.
CC6.6 — protection against unauthorized data exposure (prompt-level redaction lands here).
CC6.7 — restricted transmission of data to external systems (every API call to a foundation model is a transmission).
CC7.2 — monitoring for anomalies, including AI usage anomalies.
If your audit reflects a 2022-era posture toward AI ("we don't allow it"), expect a finding in 2026.
GDPR, HIPAA, and US State Privacy Laws
GDPR Article 5 — purpose limitation and data minimization apply to every prompt.
GDPR Article 25 — privacy by design covers system architecture, including the choice of AI vendor and the configuration of redaction.
GDPR Article 35 — Data Protection Impact Assessments are now expected for any "systematic and extensive" automated processing, which most enterprise AI rollouts qualify as.
HIPAA — Business Associate Agreements with AI vendors, minimum-necessary standard for prompts, audit accounting of disclosures.
CCPA/CPRA, Texas TDPSA, Colorado AI Act — automated decision-making notice and opt-out, sensitive personal information handling, and an emerging set of pre-deployment risk-assessment obligations.
The Lifecycle of Data in an AI System (And Where Governance Has to Live)
A useful way to plan an AI data governance program is to walk the lifecycle and ask, at each stage, what controls apply here?
1. Source data. Where did the data come from? Was it lawfully collected for this purpose? Is it accurate, current, and minimally scoped? — Pillar 1, plus GDPR Article 5.
2. Pre-processing and feature engineering. Have sensitive fields been masked, tokenized, or removed before they enter a training set? Is bias documented? — Pillar 3, plus EU AI Act Article 10.
3. Training and fine-tuning. Who has access to the training environment? Is the dataset versioned and audit-logged? Will the trained weights memorize regulated data? — Pillars 2, 3, 4.
4. Retrieval and grounding (RAG). What documents can the retriever surface? Are access controls preserved at retrieval time, or does the LLM see everything the retriever's service account sees? — Pillar 2. (This is where most enterprise RAG implementations leak.)
5. Prompts. What is being typed, pasted, or auto-included by an agent? Is regulated data being redacted before transmission? — Pillar 3.
6. Outputs. Is the response inspected before it returns to the user, the next agent in a chain, or a downstream system? — Pillar 3.
7. Storage and feedback. Are prompts and outputs being retained by the vendor for training? By you for audit? Are retention policies enforced? — Pillars 4 and 5.
8. Decommissioning. When the use case ends, is the data, the model, and the vendor connection actually removed? — Pillar 5.
Most enterprise programs cover stages 1–3 (the classical data governance stages) and stage 7 (storage). Stages 4, 5, 6, and 8 are where AI data governance is genuinely new — and where most of the operational risk now lives.
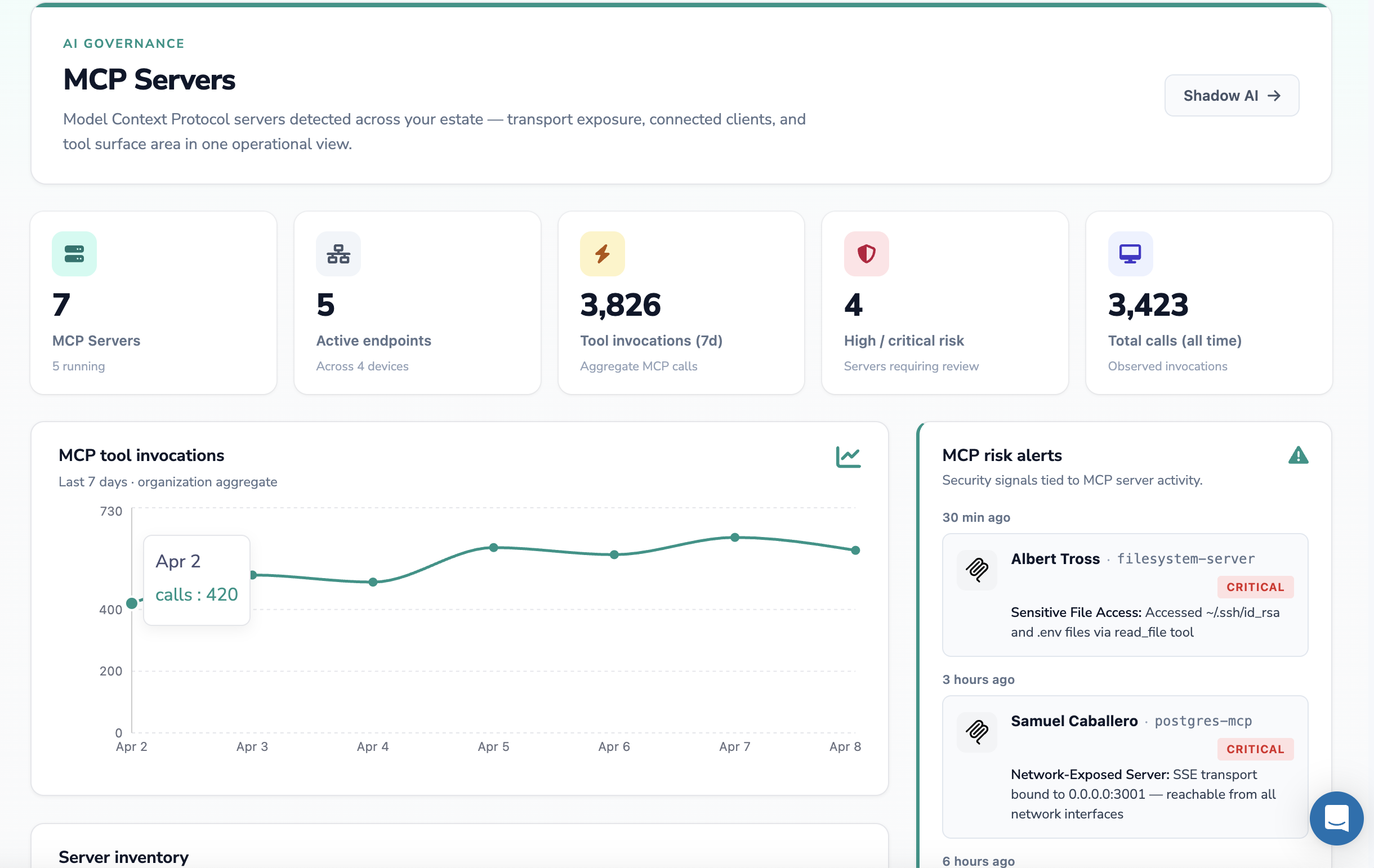
✨ MCP Servers: The Newest Data Governance Surface
If you are governing AI in 2026, you are governing MCP servers — whether you know it or not.
Model Context Protocol servers let AI assistants talk to local files, databases, internal APIs, and other systems on behalf of a user. They are running, today, on developer laptops across most engineering organizations. Each one is a small, often unauthenticated bridge between an AI model and your data.
MCP servers introduce a new class of data governance surface: AI-driven access to files, databases, and APIs that no traditional data security tool was built to inventory.
The governance questions for MCP are the same five pillars, applied to a new substrate:
Discovery: where are MCP servers running, who installed them, what tools do they expose?
Access: do they require auth, are they bound to localhost or exposed on a network port?
In-flight protection: when an MCP tool reads ~/.ssh/id_rsa or a .env file, is that data inspected?
Audit: is every tool invocation logged with the user, the data accessed, and the disposition?
Lifecycle: when an employee leaves, are their MCP servers and their tokens decommissioned?
These are not exotic, future-state questions. They are operational questions for any company whose engineers have installed Claude Desktop, Cursor, or Zed in the last six months.
A 90-Day AI Data Governance Implementation Playbook
Most "implementation guides" are checklists with no time dimension. The pattern below works for a security team of one to ten people supporting an organization of 200 to 5,000.
Weeks 1–3: Visibility
Deploy AI tool discovery (browser, OAuth, SaaS, network, endpoint).
Build the AI tool inventory — sanctioned and unsanctioned.
Identify the top 20 AI tools by user count and data volume.
Run a one-time DPA gap analysis against the top 20.
Map the five most critical AI use cases (customer support, code generation, marketing, sales ops, internal search) and their data flows.
Deliverable: an inventory and a use-case data-flow map.
Weeks 4–7: Control
Roll out prompt-level redaction for the top three AI tools by usage.
Tighten OAuth scopes for the top 10 AI vendors.
Define and publish an Acceptable AI Use policy (lightweight, one page).
Configure SSO and SCIM enforcement for sanctioned AI tools.
Block or quarantine the highest-risk unsanctioned tools.
Stand up data classification at the prompt and document level.
Deliverable: measurable reduction in regulated-data exposure on the inventory's top tools.
Weeks 8–12: Assurance and Lifecycle
Wire AI audit logs into the SIEM and the GRC platform.
Map controls to NIST AI RMF, ISO 42001, EU AI Act, and SOC 2.
Run the first DPIA on the top use case.
Train the AI procurement reviewers on the five-pillar framework.
Establish a quarterly AI data governance review with security, legal, privacy, and a business sponsor.
Deliverable: a defensible program with auditable evidence, ready for the next external audit cycle.
This is not a maturity-model fantasy with five years of milestones. Ninety days is the realistic window in which a focused team can move from "we don't know" to "we have a program."
Common AI Data Governance Pitfalls (And How to Avoid Them)
Pitfall 1: Treating AI data governance as a model-governance problem. ML platform teams own model evaluation, drift, and bias. They do not, and should not, own the data flows from a sales rep's browser into ChatGPT. Owners must be assigned to the data side of the program — typically security, privacy, and data governance leaders — not the model side.
Pitfall 2: Banning AI. Bans push usage underground. Within 30 days of a ban, regulated-data exposure typically increases (now on personal devices, on personal accounts, with no logging). The data shows this is the default outcome, not the exception.
Pitfall 3: Buying a single "AI security" tool that only watches the browser. Browser visibility is necessary and insufficient. Without OAuth grant scanning, SaaS-embedded AI inspection, file/document classification, and audit integration, you will close one window while three others stay open.
Pitfall 4: Writing a 40-page policy and calling it a program. The policy is the smallest part. Without discovery, redaction, and audit infrastructure underneath, the policy is litigation cover at best and false assurance at worst. (For a one-page policy you can actually defend, see the AI Governance Policy template and the Acceptable AI Use Policy template.)
Pitfall 5: Forgetting MCP and agents. Every governance program built before late 2025 was scoped to chatbots and copilots. Agentic AI and MCP servers act on data, not just with it. Governance has to extend to actions taken on behalf of users, including write actions. (See Shadow AI: Definition, Risks, and How to Detect It for the discovery side of the MCP problem.)
Pitfall 6: Ignoring data residency and cross-border flows. Sending an EU customer's prompt to a US-hosted model is a Schrems II problem. Most enterprises are doing this in production today and have not yet mapped it.
Pitfall 7: Letting AI vendors mark their own homework. Vendor-published "trust centers" are marketing. A real vendor review reads the DPA, the sub-processor list, the model card, the security questionnaire response, and the actual contractual rights to your data — and treats every quarterly change as a re-review trigger.
✨ 🎥 Where Strac Fits in an AI Data Governance Program
Strac is a data security platform. In an AI data governance program, that means we operate at pillars 1, 3, and 4 — discovery, in-flight protection, and audit — across the surfaces where employees actually use AI: the browser, SaaS, endpoint, email, file storage, code repositories, and (now) MCP.
An AI data governance program lives or dies on coverage. Strac sits across SaaS, cloud, endpoint, email, browser, code, and GenAI tools — one control plane for every place regulated data meets AI.
Concretely:
Discovery of every AI tool, every prompt, every byte uploaded, every OAuth grant, and every MCP server, across the organization. (See Shadow AI: Definition, Risks, and How to Detect It for the discovery problem in detail.)
In-flight redaction of regulated and proprietary data at the prompt level, the file level, and inside images and documents — so the data your policy says is off-limits never reaches the model in the first place.
Audit-grade logging mapped to SOC 2 CC6, ISO 42001, NIST AI RMF, and EU AI Act Article 10, ready to drop into your existing GRC evidence trail.
Framework-agnostic: the same controls produce evidence for SOC 2, HIPAA, GDPR, ISO 42001, NIST AI RMF, EU AI Act, Texas TDPSA, and the Colorado AI Act.
Strac focuses on the data layer — where the regulated data lives and where most audits land. Model evaluation, bias auditing, and model cards typically sit with ML platform and AI ethics teams; we complement that work rather than replace it.
The five-pillar program in operation: every AI tool tracked, every risk surfaced as a finding, every finding tied to a specific user, control, and audit framework.
✅ How Strac covers AI data security across every surface
AI data governance only works if you can apply policy at every place sensitive data flows into and out of AI systems. Strac covers each surface in production:
1. Browser DLP — every prompt to Claude, ChatGPT, Gemini, Copilot, Perplexity
Strac's browser extension intercepts every prompt before it reaches the LLM API and redacts PII, PHI, PCI (cardholder data), source code, and secrets inline. The model still works — it never sees the raw sensitive data. Coverage extends to claude.ai, ChatGPT, Gemini, Microsoft Copilot, Perplexity, Mistral, DeepSeek, plus Anthropic and OpenAI APIs. See Strac Generative AI DLP and Strac Claude DLP.
2. MCP DLP — for AI agents acting on enterprise data
When a Claude, Cursor, or ChatGPT agent calls a Slack, Gmail, Google Drive, GitHub, Notion, or any other MCP server, Strac sits inline and redacts sensitive data in every tool-call response. Strac is the first DLP with native Model Context Protocol policy enforcement — most enterprise DLP vendors still have no MCP support at all. Full background: MCP DLP guide.
3. SaaS DLP and Data Discovery — across 47+ integrations
The same redaction and labeling policies apply to every SaaS surface where data lives — Slack, Google Drive, Gmail, M365, OneDrive, SharePoint, Salesforce, Notion, Jira, Confluence, GitHub, Linear, HubSpot, Asana, Zendesk, Intercom, Box, ServiceNow, and 30+ more. Continuous data discovery and classification (DSPM) inventories every personal data type across your environment and automatically applies the right sensitivity label.
4. Cloud DSPM — AWS, Azure, GCP
Strac continuously scans AWS (S3, RDS, EBS, CloudWatch), Azure (Blob Storage, SQL), and GCP (Cloud Storage, BigQuery) for sensitive data at rest. Not point-in-time scans — continuous discovery with automatic classification. The output powers compliance evidence for GDPR, HIPAA, PCI DSS, SOC 2, and ISO 27001 audits.
5. Endpoint DLP — Mac, Windows, Linux
For data egress outside the SaaS perimeter — local file shares, USB drives, screenshots, terminal output, IDE clipboards. Strac's endpoint agent enforces the same policies as the SaaS, browser, and MCP layers, with full audit logs for any sensitive data movement.
No, and the difference shows up in audits. AI governance covers the model — accuracy, bias, explainability, model risk management. AI data governance covers the data — what goes in, what comes out, who can see it, and whether you can prove any of that to a regulator. Most enterprises consume AI rather than build it, which means AI data governance is the larger and more urgent of the two for most organizations.
Do we need an AI data governance program if we don't build our own AI?
Yes — arguably more than the companies that do. Every enterprise consuming AI is acting as a data controller for the prompts and documents being shipped to third-party models. EU AI Act, GDPR, SOC 2, HIPAA, and the state AI laws apply to the use of AI, not just the building of it. The legal and audit obligations attach to you whether the model is yours, OpenAI's, or Anthropic's.
How is AI data governance different from data governance for generative AI specifically?
Generative AI is the fastest-growing surface inside the broader AI data governance discipline, and it is what most current regulation targets — but the principles extend to every AI system, including discriminative ML, computer vision, and agentic systems. A program scoped only to generative AI will not cover training data for an internal fraud model or a vision model classifying medical images. Use generative AI as the urgent slice; design the framework so it covers all AI systems.
Can we use a traditional data governance tool (Collibra, Alation, Atlan) for AI data governance?
Partially. Catalog tools handle data lineage and stewardship at rest, which is part of pillar 1. They do not inspect prompts, redact in flight, scan OAuth grants, or audit AI usage — which is most of pillars 2, 3, 4, and 5. The pattern that works is to keep the catalog as the system of record for what data exists and add an AI-aware data security platform for what AI is doing with it.
What about Microsoft Purview or Google Workspace's built-in tools?
They cover their own surfaces well — Purview inside Microsoft 365 and Defender, Google's tools inside Workspace. Neither covers cross-vendor AI usage (a Workspace customer using Claude or ChatGPT in the browser), neither inspects images or unstructured documents at the depth most regulated industries require, and neither is framework-agnostic across SOC 2, ISO 42001, EU AI Act, HIPAA, and the state laws. For most enterprises they are part of the program, not the whole program.
Is the EU AI Act actually enforceable on US companies?
Yes, for any AI system whose output is used in the EU, regardless of where the system or company is hosted. Article 10's data governance obligations apply to high-risk AI systems serving EU users, and the penalties scale to a percentage of global turnover. The pattern of US companies waiting for "real" enforcement before acting on EU law is — based on GDPR experience — an expensive way to learn.
How does AI data governance relate to a DPIA or PIA?
A Data Protection Impact Assessment is a regulatory instrument; AI data governance is the operational program that makes a DPIA possible to fill out honestly. If you cannot describe the data flows, the categories of data, the lawful basis, the retention, and the safeguards — which is what a DPIA requires — then you do not yet have an AI data governance program. The five-pillar framework is, in effect, a DPIA-ready operational structure.
What does "framework-agnostic" actually mean in this context?
That a single set of operational controls (discovery, classification, redaction, audit, vendor lifecycle) generates the evidence for SOC 2, ISO 27001, ISO 42001, NIST AI RMF, EU AI Act, GDPR, HIPAA, and the US state AI laws — without standing up a separate program for each. This is the only economically viable approach for a security or compliance team operating against more than two frameworks.
How do we measure success?
Three metrics that matter, in order:
Coverage: percentage of AI tools in use that are inventoried, classified, and have a policy. Target: 95%+.
Exposure: count of regulated-data prompts blocked or redacted per month, trending down as users learn what's allowed and what isn't.
Auditability: time to produce evidence for a given AI control on demand. Target: under one hour.
If you cannot measure these, you have a policy, not a program.
The Bottom Line
AI data governance is what data governance, data security, and AI governance look like when they are forced to operate on the same data, in real time, under regulatory scrutiny. It is not a new department, a new tool category invented to sell software, or a passing concern. It is the discipline that determines whether your AI strategy survives its first audit, its first incident, and its first regulator letter.
The companies getting this right in 2026 are not the ones with the most elaborate AI ethics committees. They are the ones who treated the data layer as the load-bearing layer — built the inventory, deployed the redaction, wired the audit log, mapped the frameworks once, and got back to running the business.
If you are building this program now: start with discovery, move quickly to in-flight controls, and let the audit trail accumulate from day one. The frameworks will keep arriving. The data flows are already there.
Discover & Protect Data on SaaS, Cloud, Generative AI
Strac provides end-to-end data loss prevention for all SaaS and Cloud apps. Integrate in under 10 minutes and experience the benefits of live DLP scanning, live redaction, and a fortified SaaS environment.

.webp)


















.gif)
