GDPR for AI Systems: 2026 Compliance Guide (with EU AI Act Updates)
How to make AI systems GDPR-compliant in 2026 — the practitioner roadmap covering EU AI Act overlap, EDPB Opinion 28/2024, DPIAs, data minimization, sub-processor cascades, and the technical controls lawyers don't explain.
GDPR was written in 2016 for databases. AI systems — LLMs, agents, MCP servers — break almost every principle by default. The good news: GDPR doesn't need new rules; it needs new technical controls at the prompt and tool-call layer. This guide is the practitioner roadmap: how GDPR and the EU AI Act overlap in 2026, the 7 articles AI most often violates, what EDPB Opinion 28/2024 actually changed, and the concrete technical implementation layer (data minimization before the prompt leaves, audit logs per tool call, DPIA + FRIA combined) that turns legal obligations into deployed controls.
TL;DR
GDPR was written in 2016 for databases. AI systems — LLMs, agents, MCP servers — break almost every principle by default. The good news: GDPR doesn't need new rules; it needs new technical controls at the prompt and tool-call layer. This guide is the practitioner roadmap.
What changed for GDPR and AI in 2024–2026
If you're reading older "GDPR and AI" articles, they're already outdated. Five things shifted the ground between 2024 and 2026:
EU AI Act entered into force (Aug 1, 2024). Prohibited practices became applicable on Feb 2, 2025. General-Purpose AI obligations became applicable on Aug 2, 2025. Most high-risk system obligations apply from Aug 2, 2026. The AI Act does not replace GDPR — it stacks on top. Both apply to any AI system processing personal data of EU residents.
EDPB Opinion 28/2024 (Dec 18, 2024) — the European Data Protection Board's landmark opinion on AI models and GDPR. Key holdings: (a) most AI models are not anonymous and therefore remain in scope of GDPR; (b) "legitimate interest" as a lawful basis for training on personal data is much harder to justify than vendors had assumed; (c) unlawfully trained models can taint downstream deployments. Read it here: EDPB Opinion 28/2024.
Garante (Italian DPA) v. OpenAI — €15M fine (Dec 20, 2024) for ChatGPT GDPR violations: no lawful basis for training-data processing, breach notification failure, inadequate age verification. First major regulator hit on an LLM provider. Garante press release.
Hamburg DPA on Microsoft Copilot (2024–2025) — guidance that employers deploying Copilot must complete a DPIA, document the lawful basis, and assess automated-decision-making implications under Article 22.
EU "Digital Omnibus" simplification package (2025–2026) — the European Commission is consolidating digital regulation overlap. Most of the changes affect reporting harmonization, not the core GDPR obligations for AI.
When we audit customer AI deployments, the same articles get tripped over and over:
GDPR article
What it requires
How AI breaks it
Required control
Art. 5(1)(c) — Data minimization
Process only what's necessary
Teams paste entire CRM exports, full customer messages, source code into prompts
Pre-prompt redaction; data minimization at the LLM boundary
Art. 6 — Lawful basis
Identify a valid basis per processing activity
Most teams have no lawful basis on file for sending personal data to Claude / ChatGPT
DPIA + lawful-basis registry per AI system
Art. 22 — Automated decision-making
Right not to be subject to solely automated decisions with legal/significant effect; right to explanation (Recital 71)
LLM-driven hiring filters, loan scoring, content moderation are inherently opaque
Human-in-the-loop; documented decision logic
Art. 30 — Records of Processing (ROPA)
Maintain a register of every processing activity
AI systems are almost never listed as distinct processing activities
One ROPA entry per AI system (LLM, agent, MCP server)
Art. 32 — Security of processing
Appropriate technical and organizational measures
Prompts and responses logged in plaintext; no encryption-in-transit to LLM API
Redaction + logging at the prompt boundary
Art. 33 — Breach notification
Notify supervisory authority within 72 hours
AI agent leaks PII via a tool call and nobody notices for weeks
Real-time audit logging and alerting on AI interactions
Art. 35 — DPIA
Mandatory for high-risk processing
Most AI deployments are high-risk by Article 35(3) definitions but skip the DPIA
DPIA + (for high-risk AI Act systems) a Fundamental Rights Impact Assessment (FRIA)
Chapter V — International transfers
SCCs + supplementary measures for transfers outside EEA
OpenAI, Anthropic, Google LLMs default to US infrastructure
Contractually pin EU residency; sub-processor controls
How GDPR and the EU AI Act actually overlap
These two regulations are complementary, not duplicative. A simple mental model:
GDPR = horizontal regulation, applies whenever personal data is processed
EU AI Act = vertical regulation, applies to AI systems by risk category (prohibited, high-risk, limited-risk, minimal-risk)
If your AI system processes personal data of EU residents, both apply simultaneously. The AI Act introduces additional obligations on top of GDPR, but does not lower the GDPR bar. Areas of direct interaction:
High-risk AI systems under AI Act Article 27 require a Fundamental Rights Impact Assessment (FRIA). This is distinct from a GDPR DPIA but largely overlapping. The pragmatic move in 2026 is to combine DPIA + FRIA into a single document rather than running parallel processes.
AI Act Article 26 requires deployers of high-risk AI to ensure input data is "relevant and sufficiently representative" — a direct echo of GDPR's Article 5(1)(c) data minimization principle.
AI Act Article 10 governs training data quality and bias — overlapping with GDPR Article 5(1)(d) accuracy principle.
AI Act prohibits social scoring, real-time biometric identification in public spaces, and several other practices (Article 5). Several of these were already arguably unlawful under GDPR; AI Act makes them explicit.
This is the implementation order we recommend at Strac, based on what works at customers like UiPath, Databricks, and Crypto.com:
1. Inventory every AI system in your environment
Most teams underestimate this by 10×. The inventory must include:
LLM consoles — Claude, ChatGPT, Gemini, Copilot, Perplexity (shadow AI is rampant — most employees use 3–5 LLMs across personal + work accounts)
AI agents — Cursor, Windsurf, custom agents calling LLM APIs
MCP servers — every Model Context Protocol server connected to an agent (Slack, Gmail, GitHub, Notion, Salesforce…)
Embedded AI features — Copilot inside M365, Einstein inside Salesforce, Duet inside Google Workspace, AI features inside Slack, Notion, Zendesk
Vendor AI — third-party SaaS sending your customer data to their LLM (often via an opaque sub-processor chain)
You can't comply with GDPR for systems you don't know exist. Use a data discovery tool — see the Strac data discovery section below for one approach.
2. Establish a lawful basis per AI processing activity
Pre-2024, many teams assumed "legitimate interest" (Article 6(1)(f)) covered AI use. EDPB Opinion 28/2024 made this much harder. The three-step legitimate-interest test (purpose, necessity, balancing) now requires concrete documentation that less-invasive alternatives were considered and rejected.
Practical guidance for 2026:
For internal productivity use of LLMs (employees using Claude/ChatGPT for drafting): legitimate interest is generally defensible, but document the balancing test
For customer-facing AI processing personal data (chatbots, AI agents acting on customer requests): contract performance (Article 6(1)(b)) or explicit consent (Article 6(1)(a)) is the safer basis
For training models on personal data: assume explicit consent is required unless you've done a watertight legitimate-interest assessment — Garante's €15M fine against OpenAI is the precedent
For special categories of data (health, biometric, etc.): Article 9 applies — explicit consent or another Article 9 exception is mandatory
3. Run a combined DPIA + FRIA
Article 35 of GDPR mandates a DPIA for "high-risk" processing. Article 35(3) lists three triggers, of which AI systems frequently hit at least one ("systematic and extensive evaluation" via automated processing). The EDPB's DPIA guidelines plus your national DPA's high-risk processing list make the DPIA effectively mandatory for any meaningful AI deployment.
The AI Act adds the Fundamental Rights Impact Assessment (FRIA) for high-risk AI systems. Run them as a single combined document with shared sections (data flows, risk catalog, mitigations) and AI-Act-specific addenda (intended use, foreseeable misuse, human oversight measures, bias testing). This saves your privacy team weeks per assessment.
4. Minimize personal data before the prompt leaves your perimeter
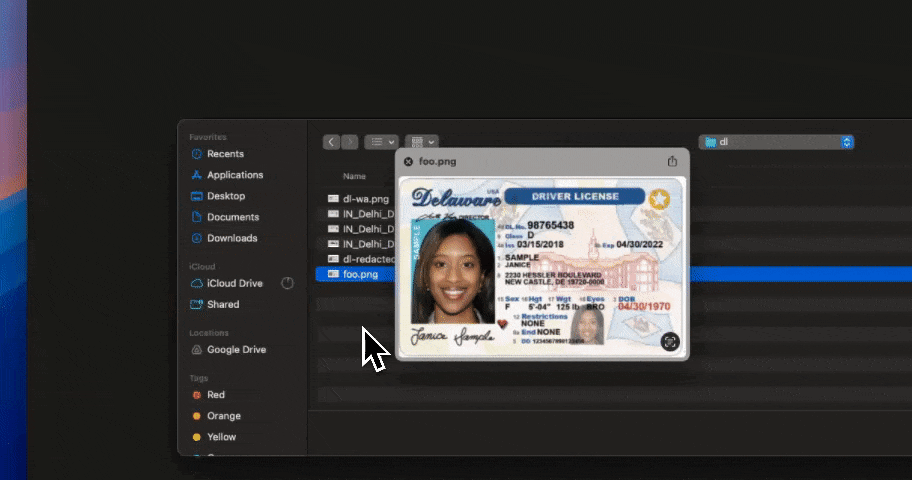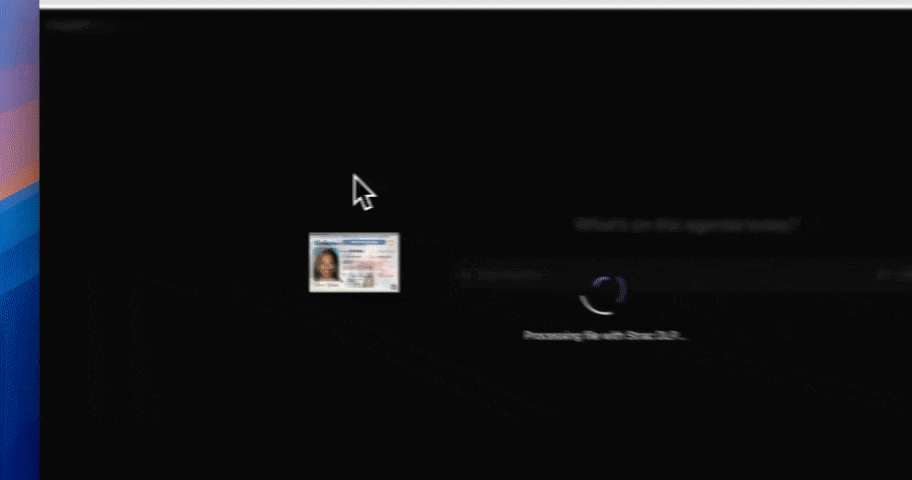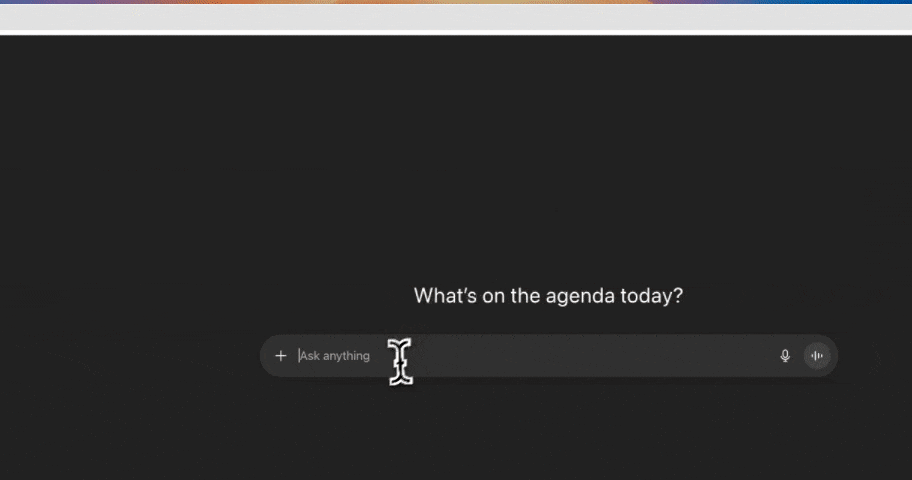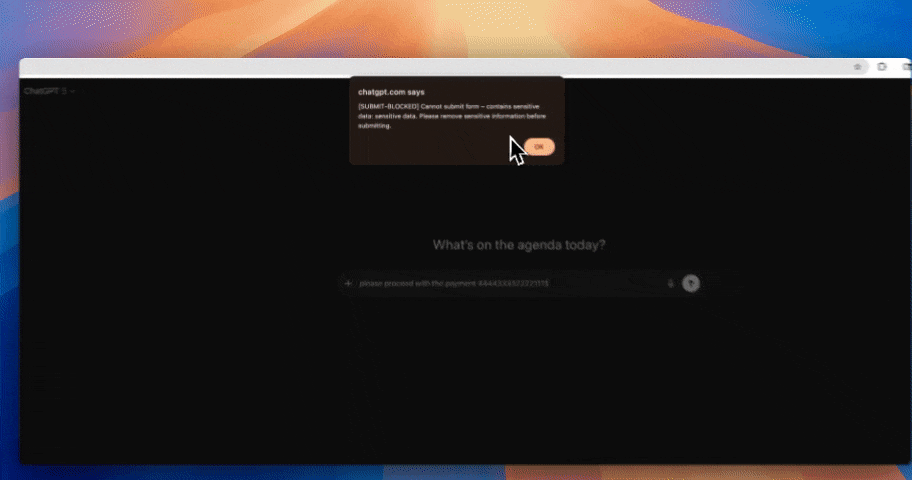
This is the single most-violated GDPR principle in AI deployments, and it's also the easiest to fix technically. Article 5(1)(c) requires that personal data be "adequate, relevant and limited to what is necessary." In practice, employees and agents send 100× more personal data to LLMs than the prompt actually requires.
The technical control is pre-prompt redaction: intercept the prompt before it reaches the model API, detect personal data (PII, PHI, financial, identifiers), and redact or tokenize it. The model still works — it just doesn't see the real data.
This is the gap most legal guides describe ("you should minimize data") without explaining the how. We cover the technical implementation in the Strac section below.
5. Maintain a ROPA entry per AI system
Article 30 records must include each AI system as a distinct processing activity. Fields to document:
Purpose of the AI processing
Categories of data subjects and personal data
Lawful basis
Sub-processors (the LLM provider — and their sub-processors)
Retention period (including provider-side logs)
International transfer mechanism (SCCs, adequacy decision, EU residency)
Technical and organizational measures (redaction, logging, access controls)
The sub-processor question is messy. When you send a prompt to Claude, Anthropic is your processor. AWS (where Anthropic runs) is a sub-processor. If you use Claude Code with a GitHub MCP server, GitHub becomes another sub-processor for that workflow. Your sub-processor list and DPA must reflect the full cascade.
6. Implement audit logging for every AI interaction
Article 32 (security of processing) and Article 33 (breach notification within 72 hours) require that you can answer: what personal data did our AI process, when, by whom, and was anything leaked?
Most teams cannot answer this. The minimum logging surface:
Every prompt sent to an LLM (or a hash of it, depending on privacy posture)
Every detection of personal data in a prompt
Every redaction action (what was redacted, by which policy)
Every tool call by an AI agent (MCP server invoked, parameters, response)
Every override (when a user bypassed a policy)
If a customer files an Article 15 subject access request asking "what AI processed my data?", you need this log to answer. If a breach happens, the 72-hour clock is brutal — you need real-time detection.
7. Vendor due diligence on every LLM provider
For each LLM you use (Anthropic, OpenAI, Google, Mistral, etc.), document:
Data Processing Agreement (DPA) signed and on file
Sub-processor list reviewed and on file
Standard Contractual Clauses (SCCs) in place for non-EU transfers, plus a supplementary-measures assessment (post-Schrems II requirement, CJEU case C-311/18)
Zero Data Retention (ZDR) option enabled where available (Anthropic offers ZDR via API; OpenAI offers no-training options; Google has similar controls)
EU residency contractually pinned where the provider offers it (Anthropic via AWS Frankfurt; OpenAI via Azure EU; Google via Vertex AI EU regions)
Business Associate Agreement (BAA) if you process PHI — separate from the DPA
We covered the Anthropic side of this in our is Claude HIPAA compliant? post, which includes the parallel HIPAA analysis.
✨ Data discovery and classification: where GDPR compliance actually starts
You cannot minimize what you do not know about. Every GDPR-for-AI program starts with continuous data discovery and classification across your SaaS, cloud, and endpoint estate. Without it:
Your ROPA is incomplete (you don't know where personal data lives)
Your DPIA is incomplete (you can't assess data flows you can't see)
Your data minimization controls are blind (you don't know what to redact)
Your breach notification is impossible (you don't know what was exposed)
Strac's data discovery and classification engine continuously scans Google Drive, OneDrive, SharePoint, Slack, Notion, Confluence, Salesforce, Zendesk, Jira, GitHub, AWS S3, Azure Blob, and 40+ other surfaces. It detects 150+ personal data types out of the box — names, emails, phone numbers, government IDs, health data, financial data, credentials, source code — and applies sensitivity labels that downstream policies (including AI policies) can act on.
🎥 See data discovery in action
Once Strac has classified your data, the same labels drive GDPR controls everywhere — including at the AI boundary.
✨ How Strac handles GDPR for AI in practice
This is the practitioner gap that most GDPR-for-AI guides skip. Lawyers explain what you must do. Strac is the technical layer that does it.
Pre-prompt redaction at the AI boundary
Every prompt sent to Claude, ChatGPT, Gemini, Copilot, Perplexity, Mistral, DeepSeek, or any LLM API is intercepted before it reaches the model. Strac detects personal data, applies your redaction policy (redact, tokenize, block with a warning, or allow with audit), and writes an immutable log of the action. The model never sees the raw personal data — which means GDPR data minimization is enforced in software, not in policy PDFs.
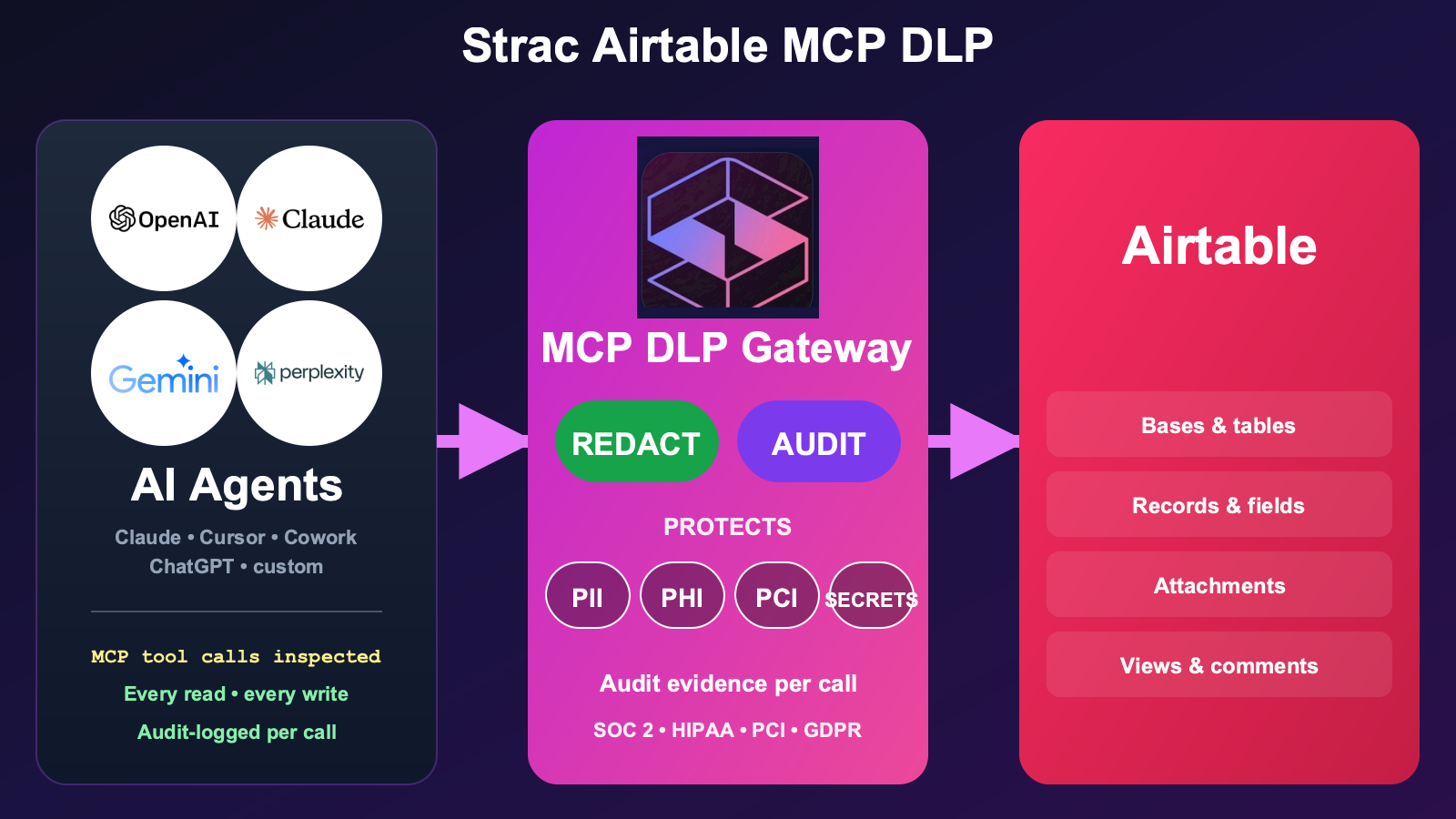
When an AI agent (Claude, Cursor, ChatGPT) calls a Slack, Gmail, Google Drive, GitHub, or Notion MCP server, sensitive data flows in and out at machine speed. Strac is the first DLP with native Model Context Protocol policy enforcement — every tool call is policy-evaluated, redacted, and audit-logged. This is the GDPR control surface that did not exist 12 months ago, and most enterprise DLP vendors do not yet cover it. See Strac MCP DLP.
SaaS DLP for the systems AI agents act on
GDPR doesn't just apply at the LLM boundary. It applies everywhere personal data flows. Strac's SaaS integrations sit on the same APIs the AI agents use, so the same redaction and labeling policy applies whether a human or an agent is acting:
Slack DLP — every message and attachment scanned and redacted
For the full picture of how Strac compares to other AI data security vendors in 2026, see our Top 10 AI Data Security Companies analysis.
Audit trails GDPR auditors actually accept
Every detection, every redaction, every override, every agent tool call is logged with timestamps, user identity, data category, and policy version. When an Article 15 subject access request lands, you can answer it. When an Article 33 breach clock starts, you have minutes-not-weeks visibility.
Strac Comply: GDPR automation alongside DLP
Once you have the technical controls (Strac DLP), you still need the compliance program — policies, evidence collection, DPIA repository, sub-processor inventory, audit responses. Strac Comply automates this layer:
GDPR control mapping — every GDPR article mapped to your implemented controls, with continuous evidence collection from your connected integrations
DPIA + FRIA templates — pre-built for AI systems, populated with your actual data flows from Strac's discovery engine
ROPA auto-generation — your processing activities are observed from real data flows, not reconstructed from memory in a spreadsheet
Sub-processor tracking — Anthropic, OpenAI, Google, AWS, Azure — all monitored for changes to their sub-processor lists with alerts
Strac Comply was built because the team dogfooded the problem — Strac itself was paying $18K/year for Vanta and decided to build the AI-native compliance platform we wanted. Now it's available to other AI-first companies.
Three 2024–2025 enforcement actions every GDPR-and-AI program should study:
Garante v. OpenAI (Dec 2024, €15M). Three core findings: (a) no lawful basis identified for using personal data to train ChatGPT, (b) inadequate transparency to users, (c) failure to notify a 2023 data breach within 72 hours. Lesson: even the biggest LLM providers get this wrong. If you're the controller deploying their model, the regulator will look at you next.
Hamburg DPA on Microsoft Copilot (2024–2025). Employers deploying Copilot must complete a DPIA, document the lawful basis, and assess Article 22 implications. Lesson: deploying a popular LLM does not transfer your controller obligations to the vendor. You remain responsible.
CNIL (France) on AI training data (ongoing 2025). CNIL has issued guidance on AI development under GDPR that is among the most practitioner-friendly anywhere in the EU. If you're building or fine-tuning a model on personal data, the CNIL guidance is required reading.
The pattern across all three: regulators are not waiting for new law. They are applying GDPR as-is to AI systems, and they are finding violations.
🌶️ Spicy FAQs for GDPR for AI
Does GDPR apply if I'm using a US-based LLM provider like OpenAI or Anthropic?
Yes — GDPR applies if the personal data being processed belongs to people in the EU/EEA, regardless of where the LLM provider is located. The provider becomes your processor; the international transfer is a separate question governed by Chapter V (SCCs, supplementary measures, EU residency options). Both OpenAI and Anthropic offer EU residency options as of 2026 — but they are not the default; you must contractually pin them.
Can I rely on "legitimate interest" as my lawful basis for using LLMs?
It depends on the use case. For internal employee productivity (drafting, summarization), legitimate interest is generally defensible if you document the balancing test. For training models on personal data, EDPB Opinion 28/2024 made legitimate interest much harder to rely on — Garante's €15M fine against OpenAI is a precedent on this exact question. For customer-facing AI processing personal data, contract performance or explicit consent is the safer basis.
Do I need a DPIA before deploying Claude or ChatGPT in my company?
Almost certainly yes if employees will be processing personal data through the model. Article 35(3) makes DPIAs mandatory for several scenarios that internal LLM use frequently triggers — large-scale processing, systematic evaluation via automated means, and the high-risk lists most national DPAs publish. The good news: a DPIA for "internal LLM use" can be a reusable template; you do not need a new one for every team.
What's the difference between a DPIA and a FRIA?
DPIAs are required under GDPR Article 35 for high-risk processing of personal data. FRIAs (Fundamental Rights Impact Assessments) are required under EU AI Act Article 27 for high-risk AI systems deployed by certain bodies. They overlap substantially. In 2026, the pragmatic approach is to combine them into a single document with shared data-flow sections and FRIA-specific addenda — saving weeks per assessment.
How do I handle a subject access request (Article 15) for data processed by an LLM?
This is genuinely hard. You must produce all personal data the data subject has had processed through your AI systems. Without prompt-level audit logging, you cannot answer. With audit logging (as Strac provides), you can retrieve every prompt and response containing that subject's data. Note that the LLM provider's own logs are typically out of scope of your direct retrieval — which is why ZDR (Zero Data Retention) configurations matter; they remove the question entirely.
Can I delete personal data from an LLM under Article 17 (right to erasure)?
Not from the model weights, no — current LLMs cannot "unlearn" specific data without full retraining. What you can and must delete: the data in your prompt logs, the data in the provider's logs (if they retain prompts), and the data in any system that fed the prompt. This is another reason ZDR configurations are important — if the LLM provider does not retain your prompts, the erasure scope shrinks to your side of the boundary.
Are AI-generated decisions subject to Article 22 (automated decision-making)?
Yes, if the AI's output has legal effects or similarly significant effects on the data subject (hiring, lending, insurance, content moderation that affects access). Article 22 requires human-in-the-loop for these decisions, plus the right to obtain meaningful information about the logic involved (Recital 71). For pure productivity use (LLM helps an employee draft a reply that the employee reviews), Article 22 is generally not triggered.
What about the EU AI Act — do I need to comply with that too?
Yes, if you deploy or develop AI systems that touch EU users. The AI Act stacks on top of GDPR. Most provisions become applicable on Aug 2, 2026, with prohibited practices already enforceable from Feb 2025 and GPAI obligations from Aug 2025. For most enterprise deployments, the practical impact is: (a) classify your AI systems by risk, (b) for high-risk systems, run a FRIA alongside your GDPR DPIA, (c) ensure human oversight and bias testing where applicable, (d) maintain technical documentation. The official AI Act portal is the canonical reference.
How does Strac help with GDPR for AI specifically?
Strac covers the technical implementation layer GDPR requires: continuous data discovery and classification (so you know what personal data exists), pre-prompt redaction at the AI boundary (so data minimization is enforced in software, not policy), MCP DLP for agent tool calls (the new surface most vendors don't cover), and immutable audit logs (so DSRs, breach notification, and regulator inquiries have answers). Strac Comply layers the program-level automation on top — ROPA, DPIA, sub-processor tracking, breach playbooks. See the Strac AI DLP page and Strac Comply to dig deeper.
Last updated: May 2026. This guide reflects EDPB Opinion 28/2024, EU AI Act enforcement timeline as of 2026, and major enforcement actions through Q2 2026. Not legal advice; consult your DPO and counsel for your specific situation.
Does GDPR apply if I'm using a US-based LLM provider like OpenAI or Anthropic?
Yes — GDPR applies if the personal data being processed belongs to people in the EU/EEA, regardless of where the LLM provider is located. The provider becomes your processor; the international transfer is a separate question governed by Chapter V (SCCs, supplementary measures, EU residency options). Both OpenAI and Anthropic offer EU residency options as of 2026 — but they are not the default; you must contractually pin them.
Can I rely on "legitimate interest" as my lawful basis for using LLMs?
It depends on the use case. For internal employee productivity (drafting, summarization), legitimate interest is generally defensible if you document the balancing test. For training models on personal data, EDPB Opinion 28/2024 made legitimate interest much harder to rely on — Garante's €15M fine against OpenAI is a precedent on this exact question. For customer-facing AI processing personal data, contract performance or explicit consent is the safer basis.
Do I need a DPIA before deploying Claude or ChatGPT in my company?
Almost certainly yes if employees will be processing personal data through the model. Article 35(3) makes DPIAs mandatory for several scenarios that internal LLM use frequently triggers — large-scale processing, systematic evaluation via automated means, and the high-risk lists most national DPAs publish. The good news: a DPIA for "internal LLM use" can be a reusable template; you do not need a new one for every team.
What's the difference between a DPIA and a FRIA?
DPIAs are required under GDPR Article 35 for high-risk processing of personal data. FRIAs (Fundamental Rights Impact Assessments) are required under EU AI Act Article 27 for high-risk AI systems deployed by certain bodies. They overlap substantially. In 2026, the pragmatic approach is to combine them into a single document with shared data-flow sections and FRIA-specific addenda — saving weeks per assessment.
How do I handle a subject access request (Article 15) for data processed by an LLM?
This is genuinely hard. You must produce all personal data the data subject has had processed through your AI systems. Without prompt-level audit logging, you cannot answer. With audit logging (as Strac provides), you can retrieve every prompt and response containing that subject's data. Note that the LLM provider's own logs are typically out of scope of your direct retrieval — which is why ZDR (Zero Data Retention) configurations matter; they remove the question entirely.
Discover & Protect Data on SaaS, Cloud, Generative AI
Strac provides end-to-end data loss prevention for all SaaS and Cloud apps. Integrate in under 10 minutes and experience the benefits of live DLP scanning, live redaction, and a fortified SaaS environment.

.webp)
















.gif)
