June 20, 2026
5
min read
PCI Data Classification; The Complete Guide for PCI DSS Compliance
Understand PCI data classification, what PCI DSS requires, and how to classify cardholder data across SaaS, cloud, and databases.
PCI data classification sits at the heart of modern PCI DSS compliance; yet it is one of the least clearly understood requirements. In today’s SaaS- and cloud-heavy environments, cardholder data no longer lives in a single payment system or database. It moves continuously across collaboration tools, support platforms, cloud storage, analytics pipelines, and third-party integrations.
This guide is designed for security, compliance, and data governance leaders who already understand PCI DSS at a high level but need clear, operational guidance on how PCI data classification actually works in practice. We will break down what must be classified, why classification determines PCI scope, where manual approaches fail, and how modern DSPM-based approaches enable continuous, audit-safe PCI data classification.
PCI data classification is the structured process of identifying, categorizing, and labeling data that falls under PCI DSS requirements so that appropriate controls can be applied. Unlike generic data classification frameworks, PCI data classification is compliance-driven and tightly scoped.
At its core, PCI data classification answers three critical questions:
According to guidance from the PCI Security Standards Council, organizations must understand where cardholder data is stored, processed, or transmitted to correctly define scope. Classification is how that understanding becomes operational and provable.

PCI data classification has shifted from a governance exercise to an operational necessity. Cardholder data now appears in far more places than traditional payment infrastructure, often unintentionally. Support agents paste PANs into tickets, customers upload payment screenshots, finance teams export CSVs, and logs replicate sensitive fields across systems.
Several forces make PCI data classification unavoidable today:
Payment-related data now flows through CRMs, help desks, collaboration tools, and analytics platforms.
Auditors expect organizations to clearly justify PCI scope and prove where cardholder data exists.
Accurate classification is the only defensible way to reduce PCI scope and avoid over-securing non-PCI systems.
Knowing exactly where PCI data lives limits blast radius when incidents occur.
In practice, PCI data classification becomes the backbone of PCI data governance. Every encryption policy, access control, logging requirement, and DLP rule depends on it.
In modern organizations, PCI data classification must extend beyond traditional databases and payment systems. Cardholder data routinely appears in:
Effective PCI data classification therefore requires continuous visibility across SaaS, cloud, and data platforms. Static documentation is no longer sufficient.
👉 Read more about How to Discover and Classify PCI Data for Compliance
PCI DSS focuses on specific categories of sensitive data. Accurate PCI data classification ensures each category is identified and governed correctly, wherever it appears.
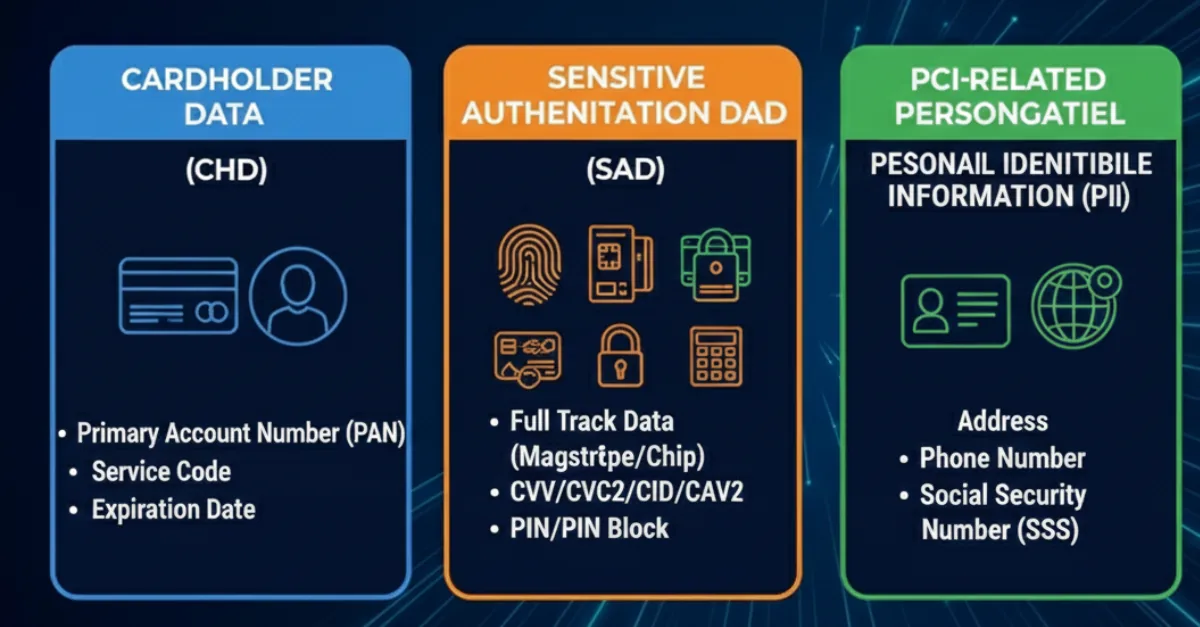
This is the primary focus of PCI DSS. CHD includes:
Any system that stores, processes, or transmits CHD is automatically in PCI scope.
SAD is even more tightly restricted and includes:
SAD must never be stored after authorization. PCI data classification plays a critical role in detecting and preventing accidental storage.
While not all PII is CHD, PCI-related personal data often appears alongside payment information. Examples include:
Classifying PCI-related PII helps organizations apply appropriate safeguards and avoid unintentional scope expansion.
PCI DSS does not explicitly mandate a control called “PCI data classification,” but it repeatedly requires organizations to identify, document, and control cardholder data. In effect, PCI data classification becomes mandatory in practice.
Key expectations include:
From an audit perspective, “evidence” matters. This includes discovery results, classification labels, access mappings, and remediation actions. Without systematic PCI data classification, producing this evidence becomes manual, slow, and risky.
Manual PCI data classification breaks down not because teams lack intent, but because modern environments change constantly. New SaaS tools are adopted, integrations are added, and data is copied and reshared every day.
Common failure points include:
Data appears in places never accounted for in original inventories.
Spreadsheets quickly become outdated and unreliable.
Manual tagging introduces gaps that surface during audits.
Classification happens too late, under time pressure.
As PCI data sprawl increases, manual approaches become a compliance risk rather than a safeguard.
Data Security Posture Management changes how PCI data classification is executed. Instead of relying on periodic reviews, DSPM makes classification continuous and discovery-driven.
A modern DSPM-based approach enables:
This approach ensures PCI data classification stays accurate over time, even as environments evolve. It also enables faster response to policy violations and reduces the operational burden on security teams.
PCI data classification becomes significantly more effective when discovery, classification, and remediation are unified. This is where Strac plays a central role.
Strac enables PCI data classification by combining DSPM and DLP into a single, agentless platform. Instead of relying on manual tagging or static rules, Strac continuously discovers and classifies PCI data across SaaS, cloud storage, data warehouses, and APIs.
Key ways Strac supports PCI data classification include:
By automating PCI data classification and keeping it continuously updated, Strac helps organizations reduce PCI scope, simplify audits, and minimize exposure without slowing down business operations.
Effective PCI data classification follows a few consistent principles that scale across environments.
Best practices include:
Define what constitutes PCI data and where it is allowed to exist.
Always identify data locations before applying labels or controls.
Classify data based on access, sharing, and usage; not just patterns.
Reassess classifications automatically as data moves.
Structured guidance from the National Institute of Standards and Technology reinforces the importance of consistent classification models backed by automation and monitoring.
PCI data discovery and PCI data classification work together but serve different purposes.
Discovery must always come first. Without it, classification is speculative. Together, discovery and classification form a continuous workflow that supports scope definition, control enforcement, and audit readiness.
PCI data classification is no longer optional or static; it is a living process at the core of PCI DSS compliance. Organizations that rely on manual classification struggle with scope creep, audit pressure, and hidden risk. Continuous, discovery-driven PCI data classification enables real scope reduction, stronger governance, and defensible compliance across modern SaaS and cloud environments.
PCI DSS does not give you a checkbox that says “implement data classification and you’re done.” Instead, it expects you to prove you know exactly where cardholder data lives and that controls are applied only where they are needed. In practice, this means you must be able to identify, group, and govern PCI data consistently across your environment.
Auditors aligned with guidance from the PCI Security Standards Council care far more about outcomes than terminology. If you cannot demonstrate where CHD and SAD exist, how scope is defined, and how controls follow the data, you will fail the intent of PCI DSS; even if your policies look good on paper.
No; and that’s exactly where teams get into trouble. PCI DSS never uses the phrase “PCI data classification” as a standalone requirement, but it repeatedly requires you to identify, document, and protect cardholder data.
Here’s the spicy truth: you cannot meet PCI DSS requirements without doing data classification, whether you call it that or not. If you claim systems are out of scope, you must prove they don’t contain PCI data. That proof is classification; just under a different name.
Auditors do not want theory; they want evidence that reflects reality today, not six months ago. This typically includes:
Static spreadsheets and screenshots rarely survive scrutiny. Auditors increasingly expect repeatable, defensible evidence that shows your PCI data classification is accurate and current.
PCI scope reduction only works if it is provable. When PCI data classification is accurate, you can confidently say which systems never touch cardholder data; and exclude them from scope without risk.
When classification is weak or outdated, auditors default to the safest assumption: everything is in scope. Strong PCI data classification narrows the environment that must be controlled, monitored, and audited; reducing cost, complexity, and operational drag.
DSPM changes PCI data classification from a manual exercise into a continuous process. Instead of guessing where PCI data might be, DSPM platforms discover it automatically and keep classifications up to date as data moves.
With a DSPM-driven approach, PCI data classification becomes:
This is where platforms like Strac fit naturally into PCI programs. By continuously discovering, classifying, and governing PCI data across SaaS, cloud, and databases, Strac enables PCI data classification that auditors trust and security teams can actually maintain; without relying on static inventories or manual tagging.






.gif)


.webp)








