Learn how AI data classification works using AI-powered and AI-enabled techniques to automatically classify sensitive data, detect unknown document types, and reduce risk across SaaS, cloud, and GenAI environments.
AI data classification is about understanding what data means, not matching patterns.
AI-powered data classification detects known and unknown document types automatically.
AI-enabled data classification lets teams define risk using simple prompts, not brittle rules.
Classification must be continuous; data risk changes as access and usage change.
Without AI data classification, DSPM, DLP, and AI governance don’t work at scale.
As generative AI is embedded into SaaS applications, support tools, developer environments, and internal systems, sensitive data no longer stays at rest; it flows through prompts, context windows, APIs, logs, and generated outputs. In this environment, AI data classification must operate at runtime; not after exposure occurs.
Effective AI data classification combines continuous discovery with real-time enforcement, enabling security teams to detect, redact, block, or audit sensitive data as it enters and exits AI systems. Without enforcement, classification remains informational; with enforcement, it becomes a practical control that reduces AI-driven data loss across modern enterprise environments.
What Is AI Data Classification
AI data classification is the process of automatically identifying, categorizing, and risk-ranking data using machine learning and large language models; based on content, context, and behavior.
Legacy classification relied on:
File extensions
Static labels
Keyword matching
Regex patterns
That approach fails in modern environments because:
Most data is unstructured
Data lives across SaaS, cloud, endpoints, and GenAI tools
New document types appear constantly
No human actually knows all the data they have
AI-powered data classification replaces guessing with understanding.
Instead of asking:
“Does this file match a rule?”
AI asks:
“What is this file, why does it exist, and how risky is it right now?”
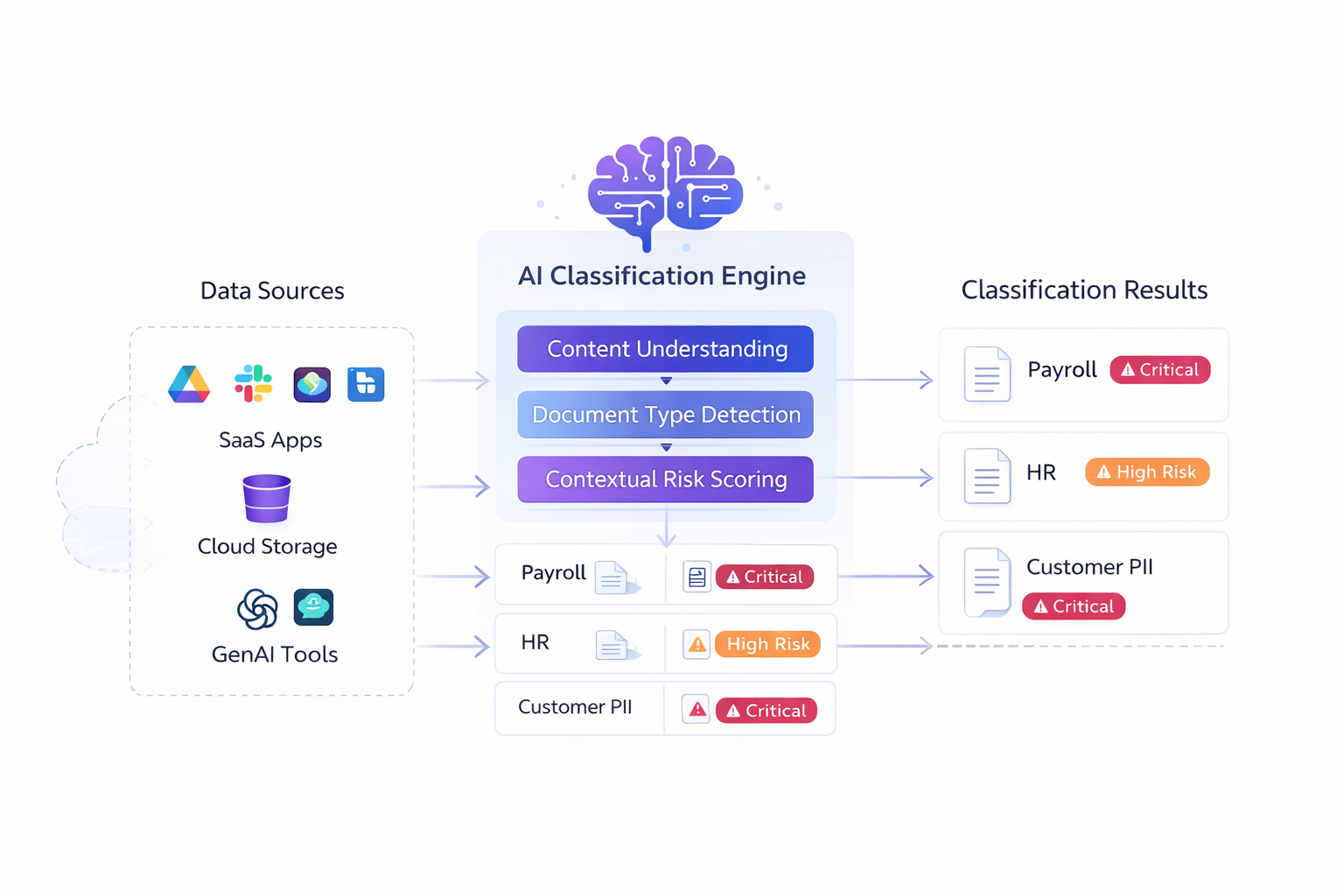
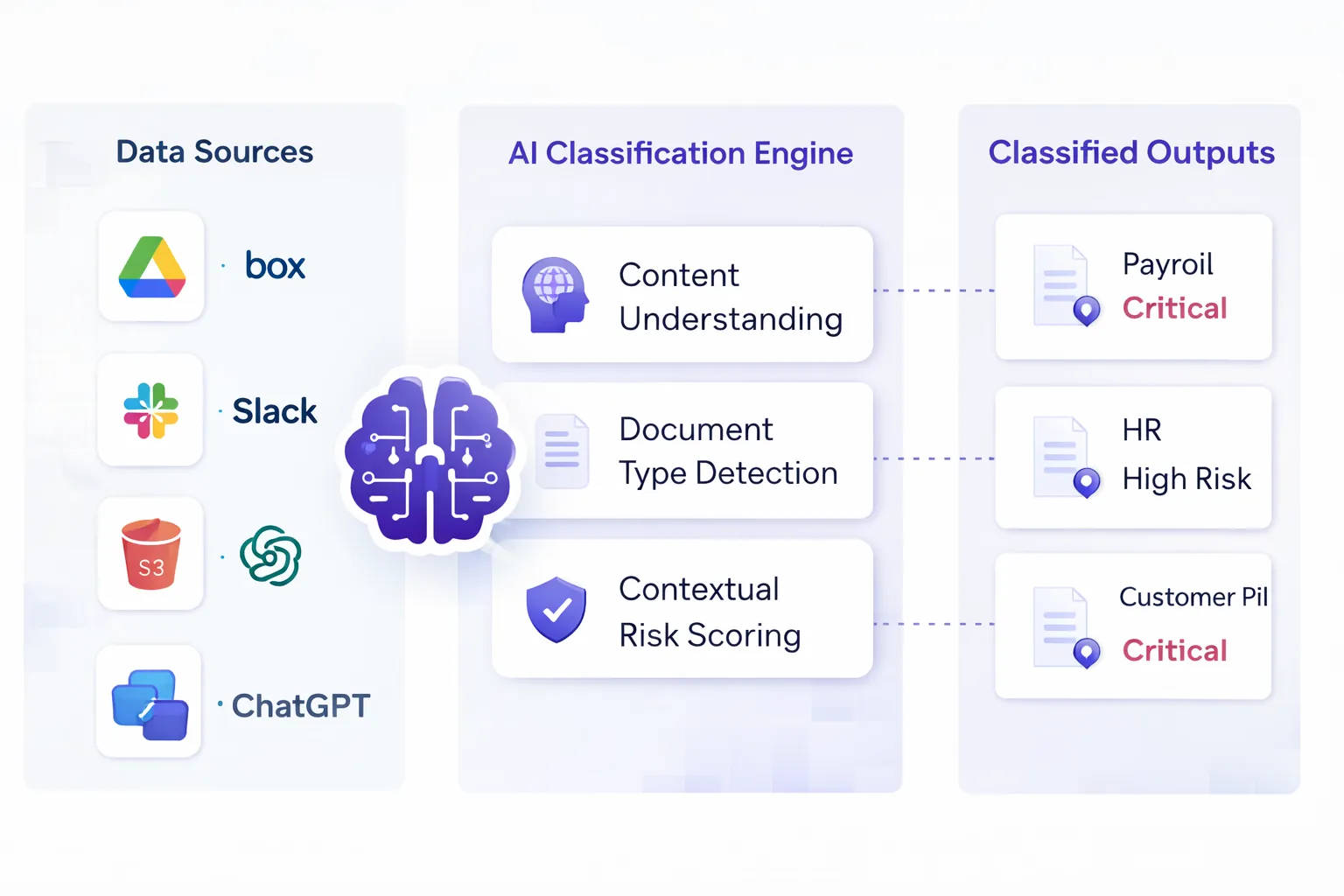
✨ How AI Data Classification Works across SaaS, Cloud, Gen AI
Strac AI Data Classification: How-It-Works
Modern ai-powered data classification systems combine multiple signals:
1. Deep Content Understanding
AI models read:
Full documents
Tables and structured sections
Scanned PDFs via OCR
Embedded metadata
This allows classification even when:
Filenames are meaningless
Templates are inconsistent
Sensitive data is partially masked
2. Semantic Pattern Learning (Not Just Keywords)
Unlike regex systems, AI-enabled data classification learns patterns unique to your environment:
How payroll files are structured internally
How HR documents differ from contracts
How real customer PII differs from test data
This dramatically reduces false positives and improves trust.
3. Contextual Signals That Actually Matter
AI data classification factors in:
Who accessed the data
From which app or cloud account
Whether it was shared externally
Whether it was uploaded to GenAI
How frequently it’s accessed
This is why classification must be continuous, not one-time.
Types of AI Data Classification Methods
AI data classification helps organizations automatically identify and label sensitive information such as PII, PHI, or financial data. Instead of relying only on manual tagging or simple rules, AI data classification uses machine learning to analyze patterns in data and determine whether it should be classified as sensitive, internal, or public.
Here are the main types of AI data classification used today:
1. Supervised AI Data Classification Supervised AI data classification is trained using labeled examples. You show the system what sensitive data looks like; such as customer emails, credit card numbers, or personal identifiers; and it learns to recognize similar patterns in other data.
2. Unsupervised AI Data Classification Unsupervised AI data classification looks for patterns without predefined labels. It groups similar data together, which can help teams discover sensitive data types they didn’t even know existed.
3. Semi-Supervised AI Data Classification Semi-supervised AI data classification combines both labeled and unlabeled data. A small number of labeled examples guide the model while it analyzes larger datasets, reducing the amount of manual work required.
4. Human-in-the-Loop AI Data Classification Human-in-the-loop AI data classification improves over time with analyst feedback. When security teams review and correct classifications, the system learns from those decisions and becomes more accurate as it runs.
Security Benefits of AI Data Classification
AI data classification helps organizations continuously discover and protect sensitive data across cloud, SaaS, and internal systems. Instead of relying on manual tagging or static rules, AI data classification automatically identifies where sensitive information lives and how it moves across your environment.
Here are the main security benefits of AI data classification:
1. Automatic Discovery of Sensitive Data AI data classification continuously scans systems to find sensitive information such as PII, PHI, payment data, or internal business records; even when teams don’t know it exists.
2. Stronger Access Control Once AI data classification labels data as sensitive, organizations can automatically enforce policies so only authorized users or systems can access it.
3. Easier Compliance AI data classification helps map data to regulatory frameworks like GDPR, HIPAA, or PCI DSS, making it easier to generate compliance reports and identify risks early.
4. Better Data Loss Prevention With AI data classification, security tools can automatically block or remediate risky actions when sensitive data is shared, moved, or exposed.
5. Faster Incident Response When a security event occurs, AI data classification immediately shows what type of data is involved and how sensitive it is, helping teams respond faster.
6. Fewer False Positives Because AI data classification analyzes context and patterns; not just simple regex rules; it can distinguish real sensitive data from random numbers or test data, reducing alert noise.
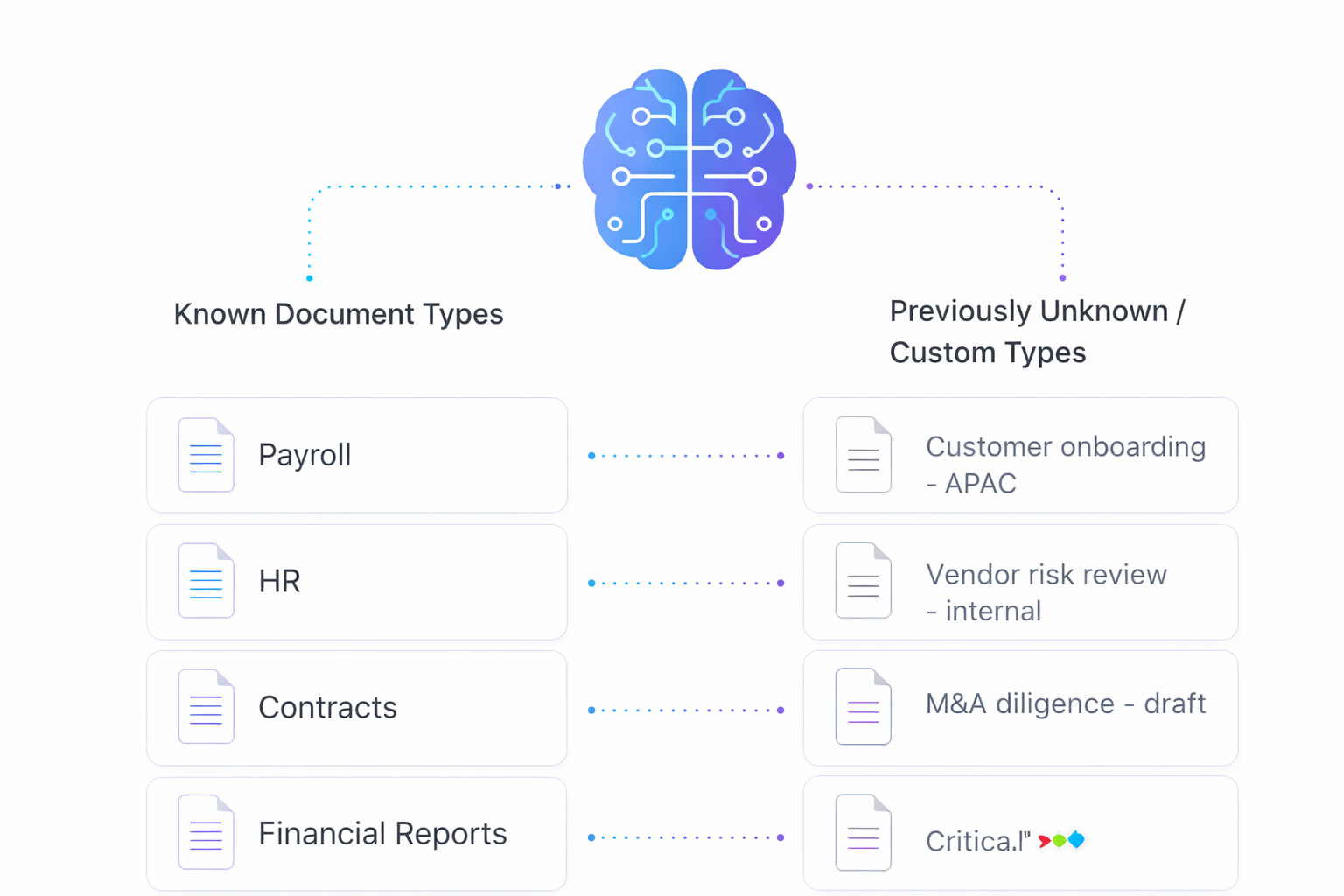
✨ AI Data Classification Automatically Detects Corporate Document Types
Strac AI Data Classification: Detecting Known and Unknown Document Types
This is the biggest shift most teams underestimate.
AI-powered data classification can automatically identify standard document categories, such as:
Payroll
HR
Tax
Contracts
Customer PII
Financial reports
Medical records
Source code
But more importantly…
👉 AI data classification can detect previously unseen or custom document types, for example:
“Customer onboarding – APAC”
“Vendor security review – internal”
“M&A diligence – draft”
“Support escalation summary”
No upfront taxonomy. No manual tuning. No brittle templates.
✨ From AI Data Classification to Business Risk (Customer-Aligned Model)
Strac AI Data Classification: Business Risk Mapping
This is how modern security teams actually want classification to work.
Step 1: AI Discovers and Classifies Everything First
Before writing policies, AI data classification scans your environment and tells you:
What sensitive data exists
What document types exist (including unknown ones)
Where this data lives (SaaS, cloud, endpoints, GenAI)
No assumptions. No guessing.
Step 2: Define Risk Using Simple Prompts (Not Rules)
Once visibility exists, teams define risk using business-aligned prompts.
Real examples customers use:
“Payroll files created in the last 12 months → Critical”
“HR documents accessed by non-HR users → High risk”
“Files with SSN + bank account → Critical regardless of age”
This is AI-enabled data classification in practice:
Human intent
AI execution
Fully auditable
Step 3: Continuous Re-classification as Context Changes
A critical insight:
Classification is not static. Risk evolves.
AI data classification continuously adapts when:
Access changes
Sharing expands
Files move to GenAI tools
Employees change roles
Yesterday’s “Low Risk” file can be today’s incident.
✨ AI Data Classification Labels Must Travel With the Data
Strac Data Labeling
A key best practice top platforms follow:
Classification metadata should persist and follow the data, using:
Labels are not just labels — they’re enforcement triggers.
AI Data Classification Powers DSPM, DLP, and AI Governance
Every modern security question depends on AI data classification:
Where is sensitive data?
What kind of data is it?
Who has access?
Is that access appropriate?
Is data leaking into SaaS or GenAI?
Without ai-powered data classification, DSPM and DLP become reactive and noisy.
With it, teams get:
Real-time alerts
Automated remediation
Reduced blast radius
Confidence in AI usage
Real-World Use Cases for AI Data Classification
AI data classification becomes necessary once sensitive data stops living in clean tables and starts spreading across emails, chat messages, documents, tickets, cloud storage, and GenAI prompts.
Some common real-world use cases:
Discovering sensitive data across SaaS and cloud apps AI classification is used to continuously scan Gmail, Slack, Google Drive, SharePoint, Salesforce, Jira, S3, and similar systems to identify PII, PHI, PCI, and confidential business data that was never manually labeled.
Preventing sensitive data from flowing into GenAI tools As employees use ChatGPT, Gemini, Copilot, and other AI tools, AI classification is applied to prompts and file uploads to detect sensitive data before it leaves the organization.
Automating compliance without relying on employees Instead of asking users to correctly label data, AI classification automatically identifies regulated data types required under GDPR, HIPAA, PCI, and similar frameworks.
Prioritizing real data risk, not just findings When classification is combined with exposure context (public access, external sharing, broad permissions), security teams can focus on the most risky data instead of chasing thousands of low-signal alerts.
Supporting insider risk and misuse detection AI classification helps identify abnormal behavior involving sensitive data, such as unexpected downloads, sharing, or uploads to unapproved destinations.
AI Data Classification vs Rule-Based Classification
Traditional data classification is largely rule-based — regular expressions, keywords, and static patterns. AI data classification goes beyond patterns and attempts to understand context and meaning.
Here’s how they differ in practice:
Rule-based classification
Works well for clearly formatted data (credit card numbers, SSNs).
Breaks down on unstructured text, documents, and images.
Requires constant tuning as formats and business language change.
Often generates high false positives at scale.
AI-based data classification
Understands context instead of relying on exact patterns.
Performs better on unstructured data like emails, chat messages, PDFs, images, and free-form text.
Can classify sensitive data even when formats vary or are incomplete.
Reduces false positives by evaluating surrounding content.
In real deployments, most teams end up with a hybrid model: deterministic rules for high-confidence detections, and AI models for contextual and unstructured data.
Common Challenges with AI Data Classification
AI data classification is powerful, but it is not magic.
Some challenges organizations commonly run into:
Ambiguous context Certain terms look sensitive in isolation but are harmless in context. Poorly tuned models can misclassify these cases.
Changing business language and workflows As organizations adopt new tools and processes, classification models need continuous tuning to remain accurate.
Privacy and access constraints Scanning sensitive data requires careful handling to ensure the classification process itself does not introduce new risk.
Over-automation without review paths Blindly automating enforcement without human oversight can lead to unnecessary blocking or business disruption.
Successful deployments treat AI classification as a control that improves over time, not a one-time setup.
✨ Classifying Data Flowing Through AI Agents (MCP)
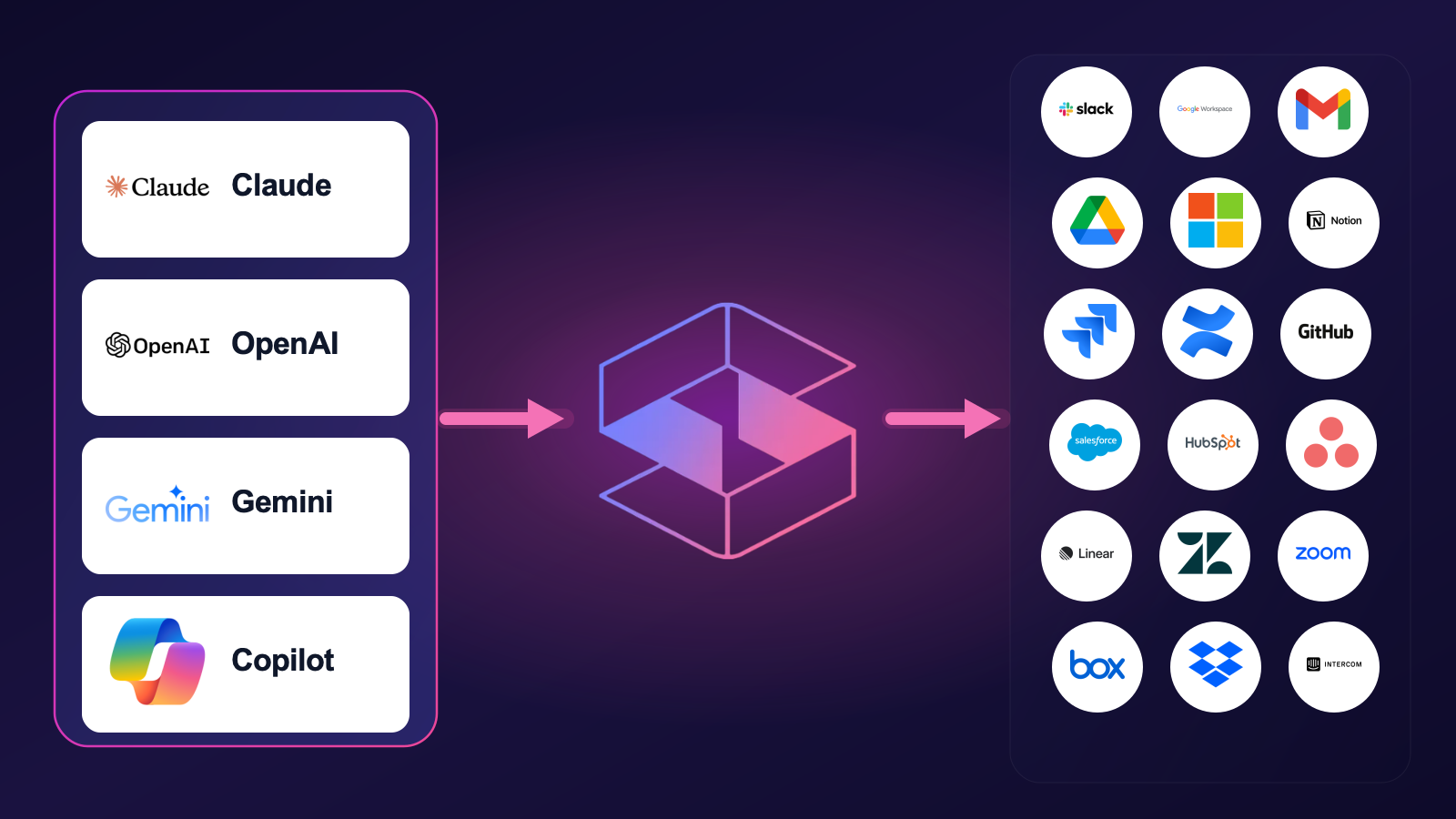
AI data classification only matters if it runs on the data your AI agents can actually reach. With Model Context Protocol (MCP), agents query your SaaS apps directly — and most classification tools never see that traffic because it terminates inside a developer’s environment. Strac classifies sensitive data flowing through every MCP connector before it reaches the model: PII, PHI, PCI, credentials, source code, and any custom data class you define. The classifier sees the same tool-call payloads the model would see, so labels stay correct end-to-end.
Strac classifies sensitive content inside every tool-call response across 18 SaaS MCP surfaces
Classifying data is easy when the data sits still. AI agents read at the speed of API calls: an agent connected to a Notion MCP server retrieves dozens of pages per minute; a Confluence MCP retrieval returns whole runbooks; a Drive MCP search traverses years of accumulated files. Classifying that content at the tool-call layer — before the model writes it into context — is a different problem than classifying data at rest in a Snowflake table.
Strac's MCP DLP runs the same classifier engine that powers Strac's SaaS DLP across each MCP integration: Slack, Google Workspace, Gmail, Drive, Microsoft 365, Notion, Jira, Confluence, GitHub, Salesforce, HubSpot, Asana, Linear, Zendesk, Zoom, Box, Dropbox, and Intercom. PII / PHI / PCI / secrets / source code detection happens on every tool-call response; image attachments are OCR'd; custom fields are inspected against your data classes. The redaction lives in the tool-call response so the classifier output never gets “forgotten” the way labels at rest sometimes are.
For healthcare-adjacent teams: Claude Cowork is the agent surface most users open day-to-day and the one Anthropic currently leaves outside its BAA. Routing Cowork against PHI-containing SaaS via MCP places that content in a non-BAA processing surface. Strac's classification + redaction at the MCP boundary keeps PHI out of the model context regardless of which Claude surface or which model provider sits behind the agent. See Is Claude HIPAA compliant? for the per-surface breakdown.
How to Choose the Right AI Data Classification Strategy
There is no single “best” AI classification approach. The right strategy depends on real risk scenarios.
Security teams should consider:
The types of data being scanned (structured vs unstructured)
Where the data lives (SaaS, cloud, endpoints, GenAI tools)
Whether classification is needed in real time or via periodic scans
Compliance and regulatory requirements
How classification integrates with DLP, DSPM, and access controls
The goal is not to classify everything perfectly — it is to reduce meaningful data risk.
✨ How Strac Covers Every AI Surface
Classification tells you what is sensitive. These four stop it leaving through AI:
One platform, four AI surfaces: the browser, the endpoint, the agent, and the estate itself.
Spicy FAQs on AI Data Classification 🔥
Can AI data classification be inaccurate or biased?
Yes. Like any model, AI classification can produce false positives or miss edge cases. This is why most mature implementations combine AI with deterministic rules and allow tuning over time.
Does AI data classification require training on customer data?
Not always. Many systems use pre-trained models and apply customer-specific tuning without storing or reusing sensitive customer content.
How does AI data classification work with DLP and DSPM?
AI classification identifies what data is sensitive, while DLP and DSPM focus on how that data is accessed, shared, and exposed. Together, they provide both visibility and enforcement/remediation
Is AI data classification just “better regex”?
No. Regex finds patterns. AI data classification understands meaning, structure, and intent. Regex alone cannot distinguish real payroll data from test samples.
Do I need to define all document types upfront for AI-powered data classification?
No. AI detects both known and unknown document types automatically, then allows you to formalize them later if needed.
Does AI data classification run continuously or only during scans?
It runs continuously. Data risk changes as access, sharing, and usage change.
Discover & Protect Data on SaaS, Cloud, Generative AI
Strac provides end-to-end data loss prevention for all SaaS and Cloud apps. Integrate in under 10 minutes and experience the benefits of live DLP scanning, live redaction, and a fortified SaaS environment.

.webp)















.gif)
