June 19, 2026
5
min read
NIST Data Classification Guidelines Explained
Understand the NIST data classification standards and learn how to apply them to enhance your organization's data security framework.
The National Institute of Standards and Technology (NIST) is a non-regulatory agency of the U.S. Department of Commerce. Founded in 1901, NIST’s mission is to promote U.S. innovation and industrial competitiveness by advancing measurement science, standards, and technology.
Over the decades, NIST has become a global authority in cybersecurity frameworks, developing best practices that organizations—both public and private—adopt to protect sensitive data and critical systems. Two key NIST documents that address data classification and security controls are:
Although originally tailored to U.S. federal agencies and government contractors, these publications have found widespread adoption across industries worldwide due to their rigorous, risk-based approach.
This publication outlines security and privacy controls for federal information systems. NIST data classification is a crucial aspect addressed in these publications. It covers a vast range of measures, from risk assessments to personnel security, helping organizations secure their data assets against internal and external threats.
This document focuses on protecting Controlled Unclassified Information (CUI) in nonfederal systems. NIST 800-171 spells out minimum security requirements and recommended guidelines to ensure confidentiality in contractor and private-sector environments.
Why They Matter:
Both SP 800-53 and SP 800-171 emphasize identifying data sets, classifying them according to their sensitivity, and applying the appropriate security controls. This categorization process, commonly referred to as NIST data classification, serves as the foundation for any robust data protection strategy.
.jpg)
NIST SP 800-60 is the foundational guide organizations use to categorize information and determine how much protection each data type requires. This framework provides structured guidance for mapping data assets to security impact levels; helping security teams create consistent policies across SaaS, cloud, GenAI, endpoints, and internal systems. When companies adopt NIST SP 800-60, they gain a reliable method for identifying which data is “Low,” “Moderate,” or “High” impact; ensuring they apply the right safeguards when implementing DLP, DSPM, and access controls.
NIST SP 800-60 categorizes information based on the consequences of a breach. Instead of guessing which data is sensitive, teams use standardized categories to evaluate confidentiality, integrity, and availability risks. As a result, organizations can align their security requirements with federal standards; simplify compliance efforts; and implement stronger, evidence-based DLP policies.
NIST SP 800-60 is especially important for modern SaaS environments where data is constantly moving. By mapping each data type to a defined impact level, companies know exactly which types of information require masking, redaction, encryption, or strict access control. This allows security teams to enforce consistent protections across collaboration tools, cloud drives, AI applications, and endpoints.

NIST’s framework revolves around the Confidentiality, Integrity, and Availability (C-I-A) triad:
These three principles guide the classification process—data that could significantly damage confidentiality, integrity, or availability must be treated with higher scrutiny and stronger controls.
When classifying data, NIST advises organizations to assign impact levels for each aspect of the C-I-A triad. These levels reflect the severity of harm that a breach or disruption would cause:
Low Impact:
Moderate Impact:
High Impact:
NIST impact levels provide a practical framework for determining how damaging a data exposure could be. Real-world examples help organizations understand which category applies to the data they use every day; enabling precise and scalable DLP policies. Each impact level reflects the magnitude of harm to individuals, operations, or an organization if the data were compromised.
Low Impact (Minor Harm)
Data that would cause limited or manageable disruption if exposed.
Examples include:
Moderate Impact (Serious Harm)
Data that could result in significant operational disruption or reputational damage.
Examples include:
High Impact (Severe or Catastrophic Harm)
Data that could cause major financial loss, legal liability, or safety risks.
Examples include:
With NIST impact levels, companies can prioritize their security investments; apply safeguards proportionally; and prevent misclassification that often results in unnecessary risk. This framework makes DLP enforcement far more accurate because every policy reflects the true sensitivity of the data being handled, regardless of where it appears across SaaS apps, cloud systems, Endpoints, or AI tools.
NIST SP 800-60 and NIST SP 800-53 reference the “High Watermark Principle.” In simple terms, if any one aspect of confidentiality, integrity, or availability is rated as High, then the overall impact level of that system or data must be classified as High.
For instance, if your data has:
The system still needs “High” controls because the highest rating in any category (here, confidentiality) sets the baseline for the entire data set.
Below is a structured approach to adopting NIST-based classification:
Solution: Use automated discovery tools to scan for data across on-premises and cloud systems.
Solution: Align NIST classification with other frameworks (e.g., ISO 27001, PCI DSS) to streamline compliance.
Solution: Prioritize High-Impact data first; apply a phased approach to classification for other categories.
Solution: Foster a security culture; provide clear benefits and success stories to stakeholders.
Solution: Schedule routine data reviews or automate scanning to detect new data or changes.
.png)
NIST + ISO 27001:
NIST + PCI DSS:
NIST + HIPAA:
NIST + SOC 2:
NIST data classification is a proven, risk-based methodology that helps organizations protect the confidentiality, integrity, and availability of their critical assets. By following NIST guidelines—and applying the High Watermark Principle—you can prioritize your security efforts effectively, meet multiple regulatory requirements, and build trust among customers and partners.
From defining impact levels to selecting appropriate controls and auditing your processes, every step of the NIST classification journey is an investment in your organization’s resilience. In a threat landscape where data breaches are all too common, adopting a robust classification framework is more than just a regulatory checkbox—it’s a strategic advantage.

NIST data classification guidelines help organizations understand the impact of data exposure; these levels define how severe the consequences of a breach would be. By knowing these categories, teams can prioritize protection controls more effectively and reduce unnecessary risk. This clarity also ensures that security and compliance frameworks stay consistent across the organization.
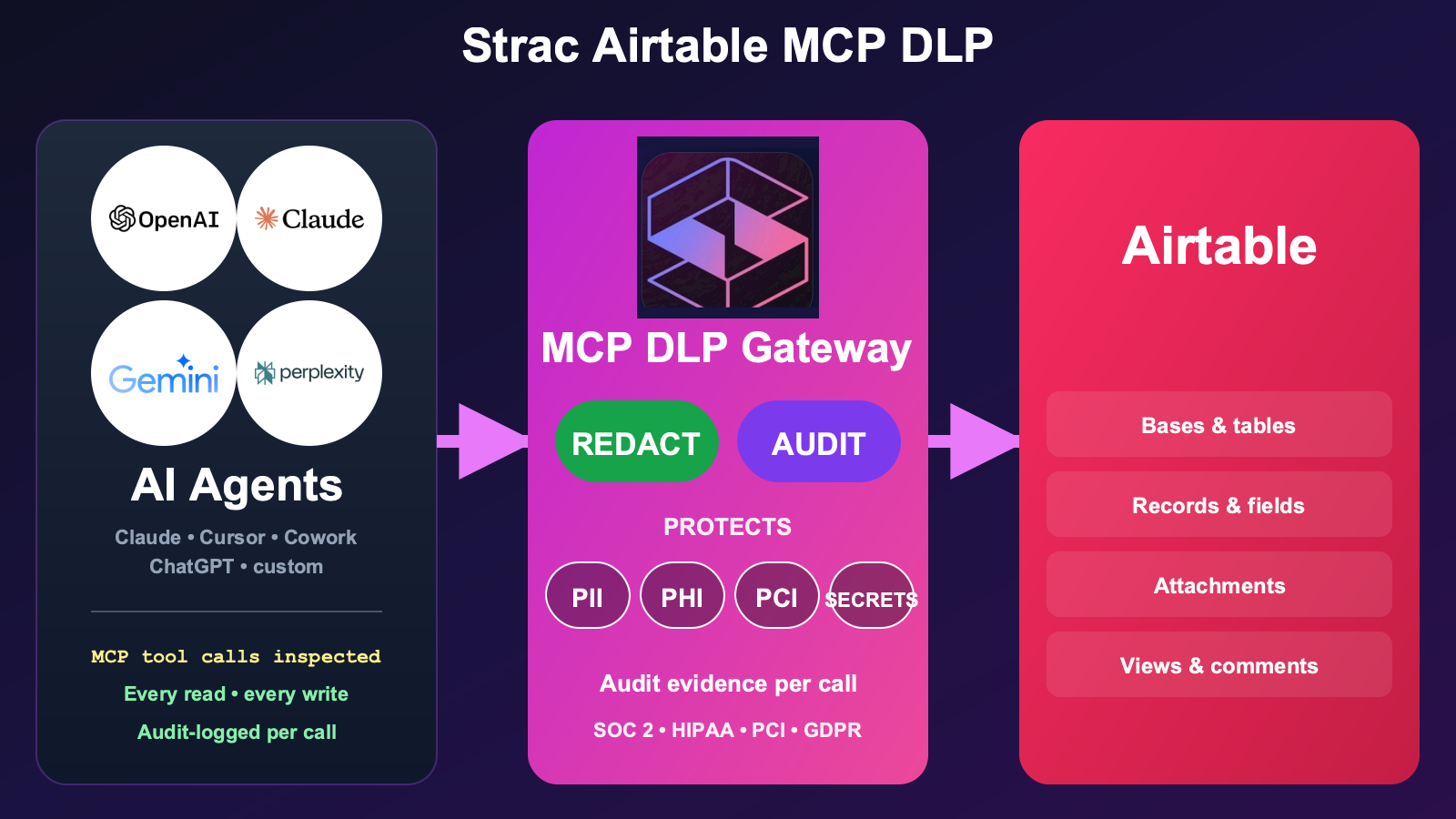
Strac maps sensitive data to NIST levels automatically, making classification precise and consistent.
NIST classification creates a structured way to identify what data needs the strongest controls; this reduces guesswork that leads to accidental exposure. It also strengthens access management; encrypting and monitoring high-impact data becomes a predictable routine. With better categorization, teams can enforce stronger policies at the exact points where data moves across SaaS, cloud, and AI tools.
Strac applies NIST-aligned controls in real time across SaaS, cloud, and GenAI environments.
NIST guidelines do not require automation; however, they strongly emphasize accuracy, repeatability, and consistent handling of sensitive data. Manual classification quickly breaks these principles; human error, subjective judgment, and inconsistent tagging weaken security posture. Automation ensures that classification scales across large systems and changing data flows.
Most modern organizations adopt ML-driven tooling because manual classification cannot meet NIST’s consistency expectations at scale.
NIST classification provides a standardized foundation that maps naturally to other regulatory requirements; this makes compliance easier to operationalize. By aligning your data to NIST impact levels, you can determine which records fall under stricter controls like PHI, cardholder data, or EU personal data. It also streamlines audits because documentation and controls become predictable and traceable.
Security teams use NIST classifications as the baseline to build their HIPAA, PCI DSS, and GDPR controls with far less complexity.
Many companies categorize data once and never revisit it; this keeps the system outdated as new SaaS apps, AI tools, and integrations enter the stack. Another major mistake is focusing only on data at rest; ignoring chat platforms, email, files, or AI prompts creates blind spots that attackers exploit. Finally, teams often classify but fail to document enforcement policies, which leaves the program incomplete.
The strongest programs revisit classification regularly; enforce controls across all data surfaces; and automate detection, tagging, and remediation where possible.
NIST data classification improves cybersecurity posture by giving organizations a structured and repeatable method to understand what data they have, how sensitive it is, and which protections it requires. Instead of treating all information equally, NIST enables teams to categorize data based on confidentiality, integrity, and availability impact; allowing security controls to match the true level of risk. This results in more accurate DLP policies, fewer blind spots, and stronger compliance alignment across SaaS, cloud, and endpoint environments.
By following NIST, companies avoid overexposing High Impact data like PHI, PCI, or authentication secrets; reduce unnecessary access to Moderately sensitive operational data; and maintain efficient workflows for Low Impact information. The outcome is a tighter, more consistent security posture that supports both prevention and rapid remediation.
NIST data classification is not mandatory for all organizations; however, it is strongly recommended and often expected in regulated or security-mature environments. Federal agencies and government contractors must follow NIST standards, and many private sector companies adopt the framework voluntarily because it provides a clear, widely recognized method for categorizing sensitive data.
Even when not required by law, NIST data classification helps organizations meet requirements under PCI DSS, HIPAA, GDPR, SOC 2, and internal governance programs. Companies adopt NIST because it simplifies risk management, strengthens DLP controls, and creates consistent security policies across every system where data is stored or shared.






.gif)


.webp)