DLP Data Classification: How Modern DLP Discovers, Classifies, and Protects Sensitive Data
Learn how DLP data classification works; how modern DLP discovers, classifies, and remediates sensitive data across SaaS, cloud, endpoints, and AI tools using ML and OCR.
DLP data classification combines automated discovery, ML/OCR classification, and real-time remediation to secure sensitive data across SaaS, cloud, endpoints, and AI tools.
DLP defines the rules; classification identifies what is sensitive; together they enforce redaction, masking, blocking, labeling, and deletion.
Modern data environments contain unstructured text, screenshots, PDFs, Slack threads, Salesforce files, and AI prompts; only ML/OCR classification can keep up accurately.
Strac unifies DSPM + DLP with agentless scanning, ML/OCR classification, and automated remediation across 40+ apps; from Slack to Salesforce to Google Drive.
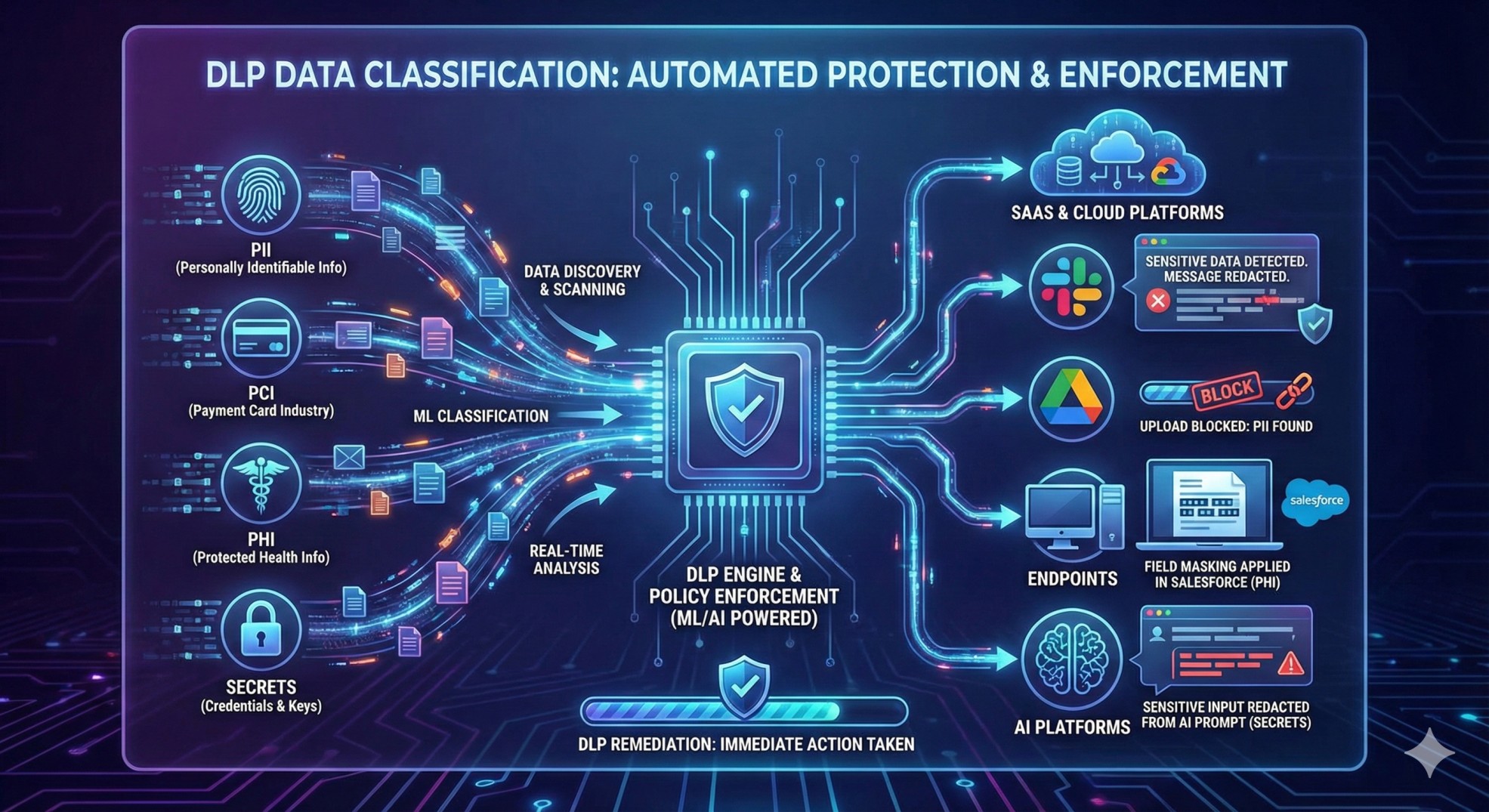
Modern security teams face an overwhelming challenge; sensitive data spreads rapidly across SaaS tools, cloud storage, email, databases, endpoints, and generative AI platforms. To stay ahead of this sprawl, organizations rely on DLP data classification, automated data discovery, and continuous scanning of unstructured documents, text, images, PDFs, and databases to understand what information they hold and how to protect it. With content-aware ML/OCR models, businesses can accurately classify sensitive data such as PII, PCI, PHI, and secrets, even when hidden inside screenshots, attachments, or messages. Once discovered and classified, modern DLP applies real-time remediation; redaction, masking, blocking, labeling, alerting, and deletion; ensuring sensitive information is secured everywhere it appears. This blog explains how data discovery, classification, and DLP work together across SaaS, cloud, endpoints, and AI tools; giving organizations the visibility, accuracy, and automation required to protect their most critical data at scale.
DLP Data Classification
DLP data classification uses the sensitivity labels (PII, PCI, PHI, secrets) to enforce automated protection policies across SaaS, cloud, endpoints, and AI platforms. This paragraph intentionally includes variations like DLP scanning, ML classification, data discovery, and DLP remediation for SEO. DLP acts immediately when sensitive data is discovered; redacting messages in Slack, blocking uploads to Google Drive, or masking fields in Salesforce.
Coverage across SaaS, cloud, endpoints, and AI tools
Data Loss Prevention Defined
Data Loss Prevention is a security strategy that prevents sensitive data from being exposed, misused, or shared improperly. To rank for data discovery, sensitive data detection, and unstructured scanning keywords, it is important to emphasize that DLP relies on automated scanning of unstructured documents; text; images; PDFs; databases; cloud drives; and SaaS tools. DLP categorizes the discovered information using ML/OCR-based classification and applies remediation such as redaction, masking, blocking, labeling, alerting, and deletion.
DLP ensures organizations maintain visibility, control, and compliance across the expanding data surface created by SaaS apps, collaboration platforms, cloud storage, endpoints, and generative AI workflows.
🎥How Does DLP Work?
DLP worksby unifying three core capabilities; data discovery, data classification, and real-time remediation. The process starts with scanning unstructured data across emails, Slack messages, Zendesk tickets, Google Drive files, Salesforce attachments, PDFs, screenshots, and even AI prompts. Once the data is discovered, ML/OCR models classify the extracted content into sensitive categories such as PII, PCI, PHI, and secrets. Finally, DLP applies automated actions such as redaction; blocking; masking; labeling; alerting; or deletion.
This three-step pipeline enables organizations to enforce consistent security policies across every application or storage system where sensitive data appears.
✨Why Is DLP Important?
DLP is crucial because modern organizations create massive amounts of unstructured content across SaaS and cloud platforms. Incorporating strong keywords such as sensitive data discovery, automated scanning, and content-aware remediation helps improve ranking. Sensitive data spreads quickly across customer support systems, productivity apps, messaging platforms, and AI tools. Without automated discovery and classification, organizations lack visibility and risk non-compliance, insider threats, and accidental oversharing.
DLP protects regulated data; prevents costly breaches; and enables businesses to comply with GDPR, HIPAA, PCI DSS, and SOC 2 while maintaining operational productivity.
Strac DLP
Benefits of a DLP Solution
A complete DLP solution provides unified data discovery, ML/OCR classification, and inline remediation at scale. This paragraph must contain strong keyword clusters like cloud DLP, SaaS DLP, endpoint DLP, and data discovery scanning. By continuously scanning unstructured files, databases, messages, and attachments, modern DLP solutions deliver visibility across the entire data lifecycle. Automated classification provides context-rich insights into sensitive data categories. Inline remediation protects data the moment it appears.
Key benefits include:
Complete data visibility; scanning unstructured documents, text, databases, files, and messages.
Regulatory compliance; automated protection for PII, PCI, PHI, and secrets supports GDPR, HIPAA, PCI DSS, and SOC 2.
Reduced insider risk; blocking or redacting sensitive messages inside Slack, email, or helpdesk tools.
Continuous protection; remediation such as masking, deletion, and real-time alerting.
What Is Data Classification?
Data classification is the process of identifying, labeling, and categorizing sensitive data to apply appropriate DLP controls. To rank for ML classification, OCR detection, and sensitive data discovery, this paragraph highlights how classification supports governance, risk management, and compliance. Organizations depend on classification to understand what data they hold; how sensitive it is; where it resides; and what rules should apply. ML/OCR helps extract text from images, PDFs, and unstructured documents for accurate classification.
Classification acts as the foundation for automated DLP policies across SaaS, cloud, endpoints, and AI systems.
Strac Data Classificaiton
Major Categories of Sensitive Data
Sensitive data falls into four core groups. This structure improves SEO around sensitive data classification and remediation.
PII; emails, phone numbers, addresses, national IDs, usernames, and profile data.
PHI; medical information, diagnoses, lab results, health insurance data.
PCI; credit card numbers, CVV, account numbers, and payment tokens.
Secrets and credentials; API keys, database passwords, OAuth tokens.
Benefits of Data Classification
Data classification enhances security posture by enabling accurate risk assessments, automated DLP controls, and consistent governance. SEO variations like sensitive data classification, automated classification, and ML classification fit naturally here. Classification labels ensure that data discovery scanning results are actionable; enabling redaction; blocking; masking; and labeling rules based on sensitivity.
Benefits include:
Improved risk visibility; automated discovery maps sensitive data across systems.
Reduced data leakage; classified content is remediated before exposure.
Stronger compliance; classification underpins GDPR, HIPAA, and PCI controls.
Lower operational noise; ML/OCR improves detection quality and accuracy.
Automated protection; classification tells DLP exactly how to respond.
✨Data Classification Best Practices
Data classification is most effective when organizations prioritize automated discovery, continuous scanning, and unified policy frameworks. To rank for data discovery scanning, ML/OCR classification, and remediation, this paragraph emphasizes end-to-end automation across unstructured data, cloud drives, SaaS tools, and AI systems.
Best practices include:
Automated discovery; continuous scanning of unstructured text, images, databases, cloud files, and messages.
ML/OCR-based classification; accurate extraction from PDFs, images, and screenshots.
Unified labels; a consistent taxonomy across all SaaS and cloud systems.
Policy-based controls; classification triggers redaction, blocking, labeling, or deletion.
Ongoing monitoring; ensure newly created data is classified instantly.
Strac Data Classification
✨How Data Classification Works
Data classification follows a three-step process: discovery, classification, and remediation. This paragraph contains variations such as scanning unstructured documents, ML classification, OCR extraction, and DLP remediation.
1. Discovery (Scanning)
Data discovery scanning identifies sensitive information across unstructured content, databases, cloud storage, email, Slack, Zendesk, Salesforce, and AI prompts.
2. Classification (ML/OCR)
ML and OCR extract and categorize sensitive data with high accuracy; reducing reliance on regex.
3. Remediation (DLP Actions)
DLP applies redaction, blocking, masking, labeling, alerting, or deletion; preventing exposure anywhere sensitive data appears.
Strac Slack DLP
✨How Do Data Classification and DLP Work Together?
Data classification and DLP work together as a single, unified protection system that gives organizations complete control over sensitive information across SaaS, cloud, endpoints, and AI tools. Classification provides the intelligence layer; it identifies what the data is, how sensitive it is, and which regulatory requirements apply. DLP provides the enforcement layer; it uses that classification to apply automated protection through real-time remediation.
Their combined workflow begins with automated data discovery scanning, which inspects unstructured text, documents, images, PDFs, databases, cloud files, and AI prompts. Next, ML/OCR-based classification analyzes the extracted content and assigns labels such as PII, PCI, PHI, secrets, or internal data. Once the sensitivity level is known, DLP instantly enforces the correct action; redaction to remove exposed data, blocking to prevent sharing, masking to limit visibility, labeling for governance, alerting for risk response, or deletion for high-risk content.
By integrating classification and DLP, organizations gain continuous, end-to-end protection over sensitive data, no matter where it is created, stored, or shared. This unified approach eliminates blind spots, reduces manual work, strengthens compliance, and ensures that sensitive information stays secure across every system where it appears.
DLP Data Classification
Bottom Line
DLP data classification is the foundation of modern data security because it unifies automated data discovery, ML/OCR-based classification, and real-time DLP remediation into a single, continuous protection cycle. In environments powered by SaaS applications, cloud storage, endpoints, databases, and generative AI tools, organizations must be able to scan unstructured documents, text, images, PDFs, and data sources to understand where sensitive information lives and how it moves. When classification labels this data as PII, PCI, PHI, secrets, or internal content, DLP can immediately apply redaction, masking, blocking, labeling, alerting, or deletion to prevent leakage and maintain compliance.
A unified DSPM + DLP platform like Strac delivers far greater visibility, accuracy, and automation than legacy, regex-based tools. Strac’s agentless data discovery scanning, content-aware ML/OCR detection, and inline remediation ensure that sensitive data is discovered, classified, and protected the moment it appears; across Slack, Google Drive, Salesforce, Zendesk, email, endpoints, and AI workflows. By combining deep scanning with intelligent classification and automated enforcement, Strac eliminates blind spots, reduces operational risk, strengthens regulatory compliance, and ensures sensitive data never slips through the cracks again.
🌶️Spicy FAQs on DLP Data Classification
What are the three types of data classification?
Data classification categories exist to help organizations understand what sensitive data they hold and how DLP should protect it through redaction, blocking, masking, labeling, alerting, or deletion. When combined with automated data discovery scanning and ML/OCR-based classification, these categories enable more accurate detection across unstructured text, documents, databases, SaaS apps, cloud storage, and AI tools. The three core types of data classification most organizations adopt are based on sensitivity and regulatory requirements.
The three types of data classification are:
Public data; information that can be shared openly without risk.
Internal data; operational information meant for employees or internal systems only.
Confidential or regulated data; high-risk information such as PII, PHI, PCI, and secrets that requires strict DLP enforcement.
These levels form the foundation for automated DLP workflows and ensure consistent application of protective controls.
How does data classification help to comply with regulations?
Data classification plays a central role in achieving compliance because it allows organizations to identify which data elements fall under GDPR, HIPAA, PCI DSS, SOC-2, or GLBA. When supported by automated data discovery scanning of unstructured and structured content, classification ensures that sensitive data is labeled correctly before any risk occurs. ML/OCR models enable precise extraction of sensitive information from PDFs, images, screenshots, and documents, making classification more accurate than manual or regex-only approaches.
Data classification enables compliance by identifying regulated information and applying the proper DLP controls, such as encryption, masking, restricted access, retention rules, or redaction. Without classification, organizations cannot reliably enforce policies, generate accurate audit logs, or maintain a defensible regulatory posture.
How does DLP help to achieve regulatory compliance?
DLP helps achieve regulatory compliance by enforcing automated policies based on the sensitivity of the data identified during classification. Through continuous data discovery scanning across SaaS apps, cloud storage, emails, endpoints, and AI tools, DLP ensures that regulated data is consistently protected. ML/OCR classification increases accuracy for documents, images, and other unstructured content, while DLP remediation applies instant controls such as blocking, masking, labeling, alerting, deletion, or inline redaction.
DLP supports compliance requirements under GDPR, HIPAA, PCI DSS, and SOC-2 by preventing accidental exposure, restricting unauthorized sharing, ensuring proper access controls, and producing audit-ready logs. When integrated with a modern DSPM platform like Strac, compliance becomes proactive rather than reactive; security teams can detect issues before violations occur.
What is data discovery?
Data discovery is the process of scanning and identifying sensitive information across all data sources, including SaaS applications, cloud storage, email systems, databases, unstructured documents, and AI tools. Modern data discovery relies on ML/OCR to extract text from PDFs, images, scanned files, and screenshots, which dramatically improves accuracy. By combining deep scanning with content-aware detection, organizations gain full visibility into where sensitive data lives, how it moves, and who has access.
Data discovery is the foundation of both DSPM and DLP because it reveals hidden risks and uncovers data sprawl. Once sensitive data is discovered, it can be classified, labeled, redacted, blocked, or deleted using automated DLP policies. Without discovery, organizations cannot protect what they cannot see.
Discover & Protect Data on SaaS, Cloud, Generative AI
Strac provides end-to-end data loss prevention for all SaaS and Cloud apps. Integrate in under 10 minutes and experience the benefits of live DLP scanning, live redaction, and a fortified SaaS environment.

.webp)
















.gif)
