June 20, 2026
7
min read
AI Data Security: Guide on Risks, Best Practices, and Compliance
Learn about AI Data Security, the Risks, Best Practices, and Compliance
AI data security refers to the practices, controls, and technologies used to protect sensitive data across AI systems; including training datasets, prompts, model interactions, and generated outputs. As organizations rapidly adopt generative AI and LLMs, AI data security has become a critical concern because data now flows through systems that were not originally designed with traditional security boundaries in mind.
Unlike conventional applications, AI systems introduce new AI security risks at every stage of the data lifecycle. Training data may include regulated PII, PHI, or PCI; prompts can unintentionally expose confidential business context; and model outputs can regenerate sensitive information in ways that are difficult to predict or control. These dynamics significantly increase the risk of AI data leakage, especially when AI tools are embedded across SaaS platforms, developer workflows, and customer-facing systems.
This guide is designed for security, compliance, and AI engineering leaders who need practical guidance, not theory. It explains how AI data protection works in real environments; outlines the most common generative AI data security risks; and breaks down best practices for securing AI training data, prompts, and outputs end to end. You will also learn how AI data governance and emerging compliance expectations intersect; and what tools and controls organizations are using today to reduce AI compliance risks while still enabling innovation.
AI data security focuses on protecting sensitive information as it moves through AI systems; from the moment data is collected and prepared, to how it is processed by models, and finally how outputs are generated, stored, and reused. Unlike traditional applications, AI systems continuously learn, infer, and regenerate information, which means data exposure risks are amplified and harder to reverse once they occur.
At its core, AI data security extends beyond classic data protection controls. Traditional data security is designed around static systems, well-defined databases, and predictable access patterns. AI systems, especially generative AI and LLM-based tools, operate dynamically; they ingest large volumes of unstructured data, interact with users in real time, and can unintentionally reproduce sensitive information. This shift requires new approaches to AI data protection, LLM data security, and ongoing AI data governance.
To understand why AI data security is fundamentally different, it helps to look at the AI data lifecycle. Each stage introduces distinct exposure risks that traditional controls were not built to handle:
Training data
This includes historical datasets used to train or fine-tune models. If sensitive or regulated data is included without proper controls, it can become embedded in the model itself, creating long-term AI compliance risks.
Prompt and input data
User prompts often contain proprietary context, customer data, or internal instructions. In generative AI environments, these inputs can be logged, cached, or sent to third-party models, increasing the risk of AI data leakage.
Inference and output data
Model responses may unintentionally reveal sensitive information learned during training or inferred from prior interactions. This is a core generative AI data security challenge because outputs are difficult to predict or fully constrain.
Logs and feedback loops
Many AI systems store prompts, outputs, and user feedback to improve performance over time. Without strict controls, these logs can quietly become high-risk data repositories.
What makes AI data security especially challenging is that data exposure in AI systems can be irreversible. Once sensitive information is used to train a model or captured in logs, it cannot simply be “deleted” in the traditional sense; the data may influence future outputs or persist across versions. This is why securing AI data across every lifecycle stage is not optional; it is foundational to building trustworthy, compliant, and scalable AI systems.
AI data security matters because AI systems dramatically expand how, where, and how fast sensitive data moves across an organization. Unlike traditional software, AI tools continuously process unstructured inputs, generate new content, and often integrate directly into business-critical workflows; this makes even small data handling mistakes scale instantly. As generative AI adoption accelerates, the consequences of weak AI data security are no longer hypothetical; they are operational, legal, and strategic risks.
From a business perspective, AI data leakage can have immediate and lasting impact. Sensitive information exposed through prompts, model outputs, or training pipelines does not behave like a traditional breach; it can surface repeatedly and unpredictably. Key risks include:
Direct financial and operational risk
Legal and regulatory exposure
Reputational damage
Competitive and intellectual property risk
One of the most overlooked issues is that alert-only security controls are insufficient for AI environments. Traditional approaches that rely on detection and notification assume humans will intervene before damage occurs. In AI systems, data moves and transforms in real time; by the time an alert is reviewed, sensitive information may already be logged, reused, or surfaced in downstream outputs.
This is why modern AI data security strategies prioritize prevention and remediation, not just visibility. Without controls that actively protect data as it flows through training, prompts, and outputs, organizations are effectively accepting AI-driven risk by design.
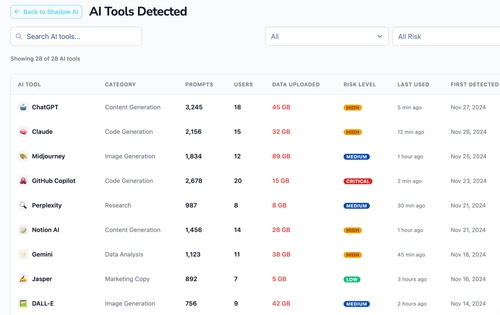
AI data security risks emerge because AI systems fundamentally change how sensitive data is created, shared, and reused across an organization. Generative AI and LLM-based tools operate across SaaS platforms, developer environments, and customer-facing workflows, often without the same guardrails applied to traditional applications. As a result, AI data protection failures are rarely isolated incidents; they tend to cascade across systems and persist over time.
One of the most common risks is sensitive data embedded in training datasets. Organizations frequently use historical logs, tickets, documents, or code repositories to train or fine-tune models. If these datasets contain PII, PHI, PCI data, or proprietary IP, that information can become implicitly encoded in the model, creating long-term AI compliance risks that are difficult to remediate.
Another major exposure vector is prompt injection and prompt leakage. Prompts often include internal context, credentials, or business logic intended only for a specific task. Malicious or poorly designed prompts can manipulate models into revealing sensitive information; while benign prompts can still be logged, cached, or reused in ways that violate AI data governance policies.
Additional high-impact AI security risks include:
Over-retention of prompts and outputs
Shadow AI usage by employees
Third-party AI tools storing customer data
Lack of visibility across SaaS and AI workflows
Together, these risks explain why AI data security cannot rely on traditional perimeter-based controls. Effective protection requires visibility, governance, and enforcement across the full AI data lifecycle; from training data to prompts, outputs, and downstream SaaS integrations.
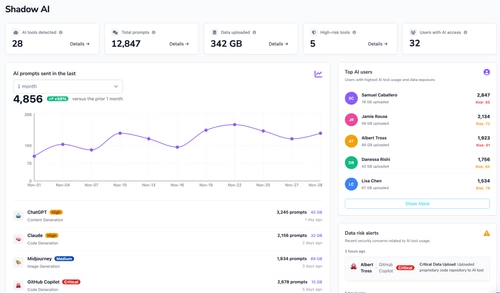
AI data security challenges arise because AI systems operate across environments that security teams were never designed to fully control. Generative AI is now embedded in browsers, SaaS platforms, developer tools, and third-party integrations, creating fragmented data flows that are difficult to observe and govern. As AI adoption accelerates, these challenges compound, making consistent AI data protection harder to enforce at scale.
One of the most significant obstacles is limited visibility into AI data flows. Security teams often lack insight into where prompts are sent, how outputs are stored, and which systems retain interaction logs. Unlike traditional applications, AI workflows span multiple tools and vendors, leaving gaps in AI data governance and increasing AI compliance risks.
Several technical and operational challenges further complicate AI data security:
Unstructured data inside prompts and files
Browser-based AI usage outside IT control
Inability to redact or block data in real time
AI adoption moving faster than governance
Together, these challenges explain why AI data security requires new, purpose-built approaches. Without visibility, real-time controls, and governance aligned to how AI is actually used, organizations remain exposed even when traditional security tools are in place.
AI data security best practices focus on preventing sensitive information from ever entering AI systems in an unsafe way; rather than trying to clean up exposure after it occurs. Because AI workflows operate in real time and across multiple tools, effective AI data protection requires controls that combine visibility, enforcement, and governance across the full data lifecycle. These practices help organizations reduce AI data leakage, manage AI compliance risks, and safely scale generative AI adoption.
A strong foundation starts with understanding what data exists and where it lives. Before enabling AI tools, organizations should implement data discovery and classification across SaaS platforms, cloud storage, and internal systems. This ensures sensitive data types; such as PII, PHI, PCI, source code, and intellectual property; are identified and governed before they are used in training or prompt workflows.
Once visibility is established, the following best practices become critical:
Least-privilege access to AI tools
Real-time inspection of prompts and uploads
Inline redaction and blocking
AI-specific DLP policies
Continuous monitoring and audit logging
User education and acceptable-use policies
When applied together, these best practices shift AI data security from reactive to preventive. They allow organizations to embrace generative AI while maintaining control over sensitive data; protecting trust, compliance, and competitive advantage.
AI data security and compliance are now tightly linked because AI systems routinely process the same regulated data types that privacy and security laws were designed to protect; then they replicate, transform, and distribute that data across prompts, outputs, logs, and downstream SaaS workflows. When AI is introduced, the compliance surface area expands instantly; what used to be a single controlled system becomes a chain of tools, integrations, and models that handle sensitive information in real time. That is why regulators and auditors increasingly view AI data security as a governance issue as much as a technical one, especially for organizations scaling generative AI in production.
Here’s how the major compliance lenses show up in real AI workflows:
GDPR risk often starts with data minimization and purpose limitation; if personal data is used to train or fine-tune models without a clear legal basis, tight purpose alignment, and defensible retention controls, you can create lasting exposure. In inference, prompts and outputs can still contain personal data; if those interactions are logged or used for improvement, you have a continuous processing activity that must be governed, not treated as one-off usage.
For healthcare and adjacent workflows, the main risk is PHI entering prompts, uploads, or support tickets routed into AI tooling. Even “helpful” use cases like summarization and drafting can become non-compliant if PHI is sent to tools without appropriate contractual safeguards and technical controls; this turns routine productivity behavior into a regulated disclosure problem.
PCI data often leaks through unstructured channels; screenshots, pasted card details, support attachments, or “debug” logs shared with AI assistants. If cardholder data or related sensitive authentication data is present in prompts or files, you now have an AI-driven propagation risk across storage, logs, and third-party systems; this is why real-time prevention matters more than post-incident cleanup.
Auditors typically want proof of control design and operation; not just policy statements. For AI, that usually means showing: who can access AI tools; what data is allowed; how prompts and uploads are inspected; what happens when policy is violated; and what audit logs exist for review. If you cannot demonstrate enforcement and traceability across AI workflows, SOC 2 becomes harder to defend.
Regulators are pushing toward structured accountability; risk management, transparency, and lifecycle controls, especially when AI systems materially affect people or handle sensitive data. Frameworks like the NIST AI Risk Management Framework emphasize managing AI risks across the lifecycle and organizational context; while EU-level approaches like the EU AI Act focus on governing AI risks with a risk-based framework.
AI accelerates how quickly sensitive data can move; how widely it can spread; and how difficult it is to contain once it is retained in logs, training data, or derived outputs. That multiplier effect is why “alert-only” monitoring tends to fail in AI environments; by the time someone reviews an alert, the data may already be captured, reused, or propagated across tools.
The practical takeaway is simple: treat AI like a regulated data processing pipeline, not a standalone feature. Align AI data governance to real workflows; then enforce it with preventive controls that can inspect, redact, or block sensitive data before it becomes an audit and regulatory problem.
AI data security tools and solutions exist because AI data security is no longer about protecting one database or one perimeter; it is about controlling sensitive data as it moves through prompts, uploads, training pipelines, outputs, and the SaaS systems those workflows touch. When teams scale AI data protection without the right tooling, the first thing that breaks is basic control: you cannot reliably see where sensitive data lives, who is exposing it to AI tools, or how to stop AI data leakage before it becomes persistent. Gartner’s framing of DSPM highlights why this matters for AI usage specifically; DSPM focuses on understanding where sensitive data is, who has access to it, and exposure to privacy, security, and AI-usage-related risks.
Below are the core tool categories to understand, without thinking vendor-first.
DSPM is about visibility and context. It helps you discover sensitive data across cloud and SaaS, classify it, and understand exposure; such as overly broad access, public links, risky sharing patterns, and unknown data stores. For LLM data security, DSPM is the “before AI” control layer; it tells you what data you have and where the high-risk sources are before they become training data or prompt inputs.
DLP is about enforcement in motion. It inspects data as users share it; pasting into prompts, uploading files, attaching documents, sending messages, or moving content between SaaS apps. For generative AI data security, DLP needs to work in real time and in the channels employees actually use (browser, chat, email, support tools, cloud drives). If it is alert-only, it is usually too late; the data has already left, been stored, or been retained in logs.
AI governance platforms operationalize AI data governance policies. They help define approved AI tools and models, acceptable-use rules, retention and logging requirements, and oversight workflows for exceptions. In fast-moving organizations, these platforms are how governance stops being a PDF and becomes a living control system that keeps pace with adoption.
This is your evidence layer. It captures who used which AI tool, what policies were triggered, what was blocked or redacted, and where data flowed afterward. These controls matter for investigations, risk reporting, and proving that AI policies are actually enforced; not just documented.
DSPM and DLP solve different halves of the same AI problem; and AI makes both halves mandatory. DSPM tells you where sensitive data is and how exposed it already is across SaaS and cloud. DLP ensures that when sensitive data starts moving into prompts, uploads, and AI-connected workflows, you can inspect and stop it in real time.
In other words: DSPM reduces “unknown risk”; DLP reduces “uncontrolled motion.” Together, they create an end-to-end system for AI data security that is practical in production; and strong enough to support AI adoption without turning every prompt into a compliance incident.
Strac approaches AI data security from a simple but critical premise; policies alone do not stop AI data leakage. In real environments, sensitive data moves too fast, across too many tools, for manual review or alert-only controls to work. Strac is positioned around real-time AI data governance that combines visibility and enforcement, allowing organizations to secure AI usage without shutting down productivity or innovation.
Instead of relying on after-the-fact alerts, Strac focuses on blocking leaks before they happen. It gives security teams clear visibility into how AI is being used across SaaS, browsers, and third-party integrations; then enforces controls directly in the workflows where prompts, uploads, and outputs occur. This makes AI data protection operational, not theoretical.
Shadow AI is one of the fastest-growing sources of AI security risks. Employees adopt AI tools independently, often without realizing how much sensitive data they are exposing. Strac addresses this by making unmanaged AI usage visible and measurable.
This allows security teams to prioritize real risk instead of chasing app inventories that lack context.
Most generative AI data security failures happen at the point of interaction; when users paste data into prompts or upload files to AI tools. Strac enforces protection at that exact moment.
By stopping sensitive data before it leaves the browser, Strac reduces risk without interrupting legitimate AI use.
OAuth-connected AI tools often create hidden “back doors” into email, files, chat, and CRM systems. Strac brings these access paths under control.
This closes gaps where AI tools can silently access sensitive data long after initial approval.
Strac’s approach applies across regulated and high-risk industries where AI adoption is accelerating:
In each case, the goal is the same; enable AI safely by enforcing AI data security where work actually happens.
The future of AI data security will not look like traditional data security with AI bolted on. AI systems require AI-native security controls that understand prompts, models, outputs, and feedback loops as first-class risk surfaces. As adoption grows, security strategies will continue shifting from passive detection to active, real-time enforcement.
Several trends are already shaping what comes next:
AI is rapidly becoming embedded in core business processes. As that happens, protecting AI data will no longer be a best practice; it will be a baseline requirement for operating responsibly, competitively, and compliantly in an AI-driven world.
AI data security is no longer optional for organizations that are serious about adopting AI at scale. As generative AI becomes embedded in everyday workflows, the risk is no longer limited to isolated mistakes; sensitive data can move instantly from prompts to models, logs, and downstream systems in ways that are difficult or impossible to undo.
The most effective AI data security strategies recognize that prevention must happen before data reaches AI models. Once sensitive information is embedded in training data, captured in prompt logs, or reflected in outputs, traditional remediation methods fall short. That is why visibility alone is not enough; organizations need data discovery, classification, and real-time enforcement working together to control how data flows through AI systems.
Organizations that invest early in AI data governance gain a structural advantage. By understanding where sensitive data lives, enforcing controls at the moment of AI interaction, and maintaining continuous oversight, they can scale AI usage with confidence. Those who secure AI data from the start will not only reduce risk; they will unlock AI’s value faster, safer, and with far fewer compliance and trust challenges along the way.
AI data security is the set of controls that protect sensitive information as it moves through AI systems; including training data, prompts, uploads, outputs, and the logs that store those interactions. AI data security matters because AI data is often unstructured and fast-moving, which increases the likelihood of accidental exposure. Strong AI data security focuses on preventing sensitive data from being used unsafely in generative AI workflows while still enabling teams to use AI productively.
AI data security typically includes discovery and classification, access controls, prompt and upload inspection, real-time blocking or redaction, and audit logging across AI and SaaS workflows. The goal is to reduce AI data leakage without turning AI adoption into a slow, manual process.
AI data security is different because AI tools turn normal “data use” into “data propagation.” Traditional data security assumes data lives in known systems with predictable access paths; generative AI changes that by letting users paste, upload, and transform data instantly across tools, models, and third-party services. This creates AI security risks that are harder to detect, harder to contain, and sometimes impossible to reverse.
The biggest difference is that AI can retain or reproduce sensitive information through training data, logs, and outputs. Once sensitive information enters those paths, cleanup is not as simple as deleting a file; the risk can persist and reappear later as AI-generated content.
AI data leakage happens when sensitive information is unintentionally shared with AI systems through prompts, uploads, training datasets, or integrated SaaS workflows. AI data leakage often starts with everyday behavior; an employee pastes customer details into a prompt, uploads a spreadsheet to summarize it, or asks an AI assistant to troubleshoot using internal logs. In those moments, sensitive data may be stored, logged, reused, or forwarded to third-party systems.
Common AI data leakage paths include:
The key issue is speed; by the time an alert is reviewed, the data may already be retained or propagated, which is why real-time enforcement is essential.
AI data security is not always named explicitly as a requirement in GDPR or HIPAA, but in practice it is increasingly necessary to meet their expectations. GDPR focuses on lawful processing, purpose limitation, data minimization, and protecting personal data; if AI tools ingest or retain personal data without proper controls, your compliance risk increases quickly. HIPAA requires safeguarding PHI; if PHI is entered into AI tools without appropriate controls and agreements, that can create serious exposure.
The practical reality is that AI multiplies compliance risk. If you cannot show that AI usage is governed, that sensitive data is controlled, and that access and retention are managed, it becomes much harder to defend compliance during audits or investigations.
Tools that secure AI data work best when they combine visibility and enforcement. AI data security requires you to know where sensitive data lives; then prevent it from being exposed through prompts, uploads, outputs, and third-party AI apps. This is why the DSPM + DLP model is becoming the dominant approach for AI data protection.
Here are the key tool categories:
If your stack only alerts after the fact, it will not keep up. The strongest AI data security programs use real-time inspection and enforcement at the exact moment data is about to reach AI models.






.gif)


.webp)








