Private LLMs: Data Protection Potential and Limitations
Private LLMs are popular as a solution to AI privacy problems, however they may not entirely protect our data as intended. Discover their data protection promise and limitations in this article.
Large Language Models (LLMs) are rapidly shaping the future of digital communication, data analysis, and automated decision-making, becoming an essential tool in both personal and professional realms. With billions of users interacting with LLMs globally, their influence extends across industries, from customer service bots to advanced analytical tools in finance and healthcare.
As these models delve into vast data troves to learn and adapt, the specter of data breaches looms large. A significant incident occurred recently when Samsung banned its employees from using ChatGPT and similar technologies after a sensitive code leak. This event highlights the critical need for robust data protection mechanisms within LLM environments.
This decision followed the leakage of sensitive code, spotlighting the critical need for robust data protection mechanisms within LLM environments. This evolving landscape highlights the urgency of integrating advanced security measures to protect sensitive information. As these technologies become deeply embedded in our digital infrastructure, safeguarding data is more crucial than ever.
Understanding the Privacy Challenges for LLMs
Large Language Models (LLMs) such as GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) process and store an immense volume of data to develop their predictive capabilities. This data often includes personal information extracted from sources like books, articles, emails, and other digital content that can contain sensitive information.
LLMs, unlike conventional applications, retain an extensive memory and lack a straightforward mechanism to "unlearn" specific data. This poses a unique challenge in a world where privacy regulations often include a "right to be forgotten," a feature inherently challenging to implement in LLMs by virtue of their design.
The risk is particularly pronounced with technologies such as Retrieval Augmented Generation (RAG), which are used with rapidly changing data sets that may contain sensitive customer, employee, or proprietary information. These challenges are manifold:
Inference from Prompt Data: When LLMs generate text based on user inputs or prompts, any sensitive information included in these prompts can influence the model’s output, risking data exposure.
Inference from User-Provided Files: In multimodal models like GPT-4, LLM systems often process documents or other files users provide. This is a common approach in RAG models, where sensitive information within these files could potentially be exposed during content generation.
Whether you're utilizing tools like ChatGPT or developing your own generative AI system, the issue of privacy remains a significant challenge. As noted by Google DeepMind researchers, no AI system, including OpenAI's GPT models, can guarantee complete data privacy, and vulnerabilities can be exposed, such as the "poem" prompt injection attack they uncovered.
Additionally, warnings from platforms like Google’s Gemini Privacy Hub highlight the risks of entering confidential information that one would not want exposed or used to enhance machine-learning technologies.
Given these risks, there is a growing push towards the use of private LLMs to mitigate potential PII leaks, highlighting the shift towards more secure, domain-specific models trained on proprietary data. This approach allows companies to control better the privacy and integrity of the data their LLMs handle, offering a tailored solution that aligns with their specific security needs and compliance requirements.
Private LLMs as a Potential Solution for LLM Privacy
Private Large Language Models (LLMs) offer a tailored approach to managing the data security challenges inherent in standard or public LLMs. Unlike their public counterparts, which are trained on diverse and widely accessible data sets, private LLMs are designed for exclusive use within a specific organization. This exclusivity allows for greater control over the training data, model tuning, and usage patterns, which can be aligned closely with the privacy policies and data security requirements of the organization.
What Are Private LLMs?
Private LLMs are bespoke models that are developed, trained, and used within the confines of a single entity. These models differ from public LLMs in several key ways:
Data Control: Organizations can use their own datasets to train the model, ensuring that the data never leaves the secure environment of the company.
Customization: Private LLMs can be tailored to understand and generate responses based on the specific context of the organization, enhancing the relevance and accuracy of the model's outputs.
Security: With complete control over the infrastructure and access mechanisms, companies can implement robust security measures that are not possible with public models.
Benefits of Using Private LLMs
Using private LLMs enhances data security and user privacy in several significant ways:
Enhanced Data Privacy: Since the data used for training and interaction does not need to be shared with external entities, the risk of data leakage is substantially reduced. Sensitive information such as personal identifiers, financial details, or proprietary knowledge remains within the organization.
Tailored Data Compliance: Private LLMs allow organizations to comply with industry-specific regulations such as GDPR, HIPAA, or CCPA more effectively. They can set up data handling and processing protocols that meet the strictest regulatory standards.
Reduced Risk of Misuse: By limiting access to the LLM to authorized users within the organization, the likelihood of the model being used to generate inappropriate content or leaking data through external interactions is minimized.
The deployment of private LLMs can be a strategic move for organizations looking to leverage the power of artificial intelligence while maintaining stringent controls over their data security and privacy frameworks. This approach not only safeguards sensitive data but also builds trust with customers and stakeholders concerned about privacy and data protection.
Assessing the Data Privacy Boundaries of Private LLMs
Deploying a Large Language Model (LLM) within a controlled environment, such as a private server or a dedicated cloud service, may offer a degree of separation from public access. Yet, model isolation does not equate to comprehensive data privacy. Consider the analogy of traditional IT security measures: wrapping a security perimeter around your infrastructure and granting implicit trust to all within this boundary is akin to building a fortress but leaving the gates unchecked. This concept, often referred to as the 'castle-and-moat' security model, is increasingly recognized as merely a foundational step in a more layered and nuanced defense strategy.
As we delve deeper, it becomes clear that relying on isolated models — whether hosted on proprietary servers, through Snowflake’s containerization service, Google's Vertex AI, or Microsoft’s Azure OpenAI Service — is insufficient for thorough data protection. This section explores the inherent privacy limitations of private LLMs, spotlighting the critical challenges organizations must navigate as they transition from prototypes and demonstrations to fully operational production systems.
Grappling with Access Control in Private LLMs
Access control within Large Language Models (LLMs) is a departure from conventional software, where user permissions can be easily managed. In the generative AI sphere, the absence of database-like structures means we can't restrict access to specific data segments as we traditionally would.
The central challenge is ensuring a model's output is permissible for the requesting user's view. Consider a support scenario: if agent Alex assists client Carla, Alex should not be privy to other clients' data. Likewise, Carla should only see her personal information and not that of another client, nor should Alex access all her details. Private LLMs don't inherently offer nuanced access control or features like data masking, which is recommended for non-production environments, as advised in best practice guidelines for AI security.
Once data enters an LLM, steering its application becomes a complex task. Thus, any team member, regardless of their role, could inadvertently access sensitive content embedded in the training data.
Streamlining Governance in Private LLM Frameworks
Private LLMs face considerable challenges in establishing robust governance protocols. They lack built-in mechanisms for detailed auditing and logging, which are cornerstones of a transparent, compliant AI operation. Crafting such mechanisms is not trivial—it's an intricate process that demands meticulous design to document interactions and ensure responsible data handling.
Furthermore, ensuring ethical use and preventing exploitation of LLM capabilities is a constant endeavor, reliant on in-depth knowledge of the system’s functions and possible weaknesses. This vigilance is critical for B2B environments where proof of training on anonymized data is as crucial as verifying consent for end-users in B2C applications.
Incorporating these governance practices into private LLMs—such as thorough auditing, user consent verification, and robust data anonymization—is a resource-intensive venture. Organizations often have to either invest heavily in internal development or face the repercussions of non-compliance and potential breaches of trust. Adequate governance is essential not just for legal and ethical alignment but also for maintaining the integrity of private LLM operations.
Navigating Privacy Compliance in LLM Deployments
Large Language Models (LLMs) inherently struggle with the precision required by privacy regulations like GDPR, which necessitates the ability to pinpoint and erase individual data elements upon request. The task of aligning with such regulations is compounded by the distributed nature of LLMs, which can spread data across multiple servers, making specific data retrieval and deletion complex.
The compliance challenges extend to global data protection laws, such as China's PIPL, which restricts international data transfer. Since LLMs often consolidate data from various locales, they can inadvertently breach such localization mandates.
When considering the rights of individuals to have their data deleted, as mandated by regulations, including GDPR and CPRA, the current LLM solutions fall short. Deletion typically means removing an entire model rather than specific personal data, a solution that's hardly practical on a case-by-case basis.
Faced with these complexities, companies find that the most effective compliance strategy is to proactively exclude sensitive data from LLMs. By embracing rigorous data management protocols from the outset, businesses can better mitigate privacy risks while preserving the model's functionality.
Balancing Costs in the Era of LLMs
Operating Large Language Models comes with substantial investments in computing power and ongoing maintenance. The elaborate networks underpinning LLMs demand high-end infrastructure, with costs spanning from initial setup to persistent energy and upkeep expenses.
The responsibilities extend to managing and updating the intricate architecture, from standard system upkeep to specialized tasks like cybersecurity, which are pivotal for data protection. With LLMs, model management is an added layer of complexity, requiring continuous refinement and expert attention for optimal performance.
The collective financial and operational implications of running LLMs necessitate thoughtful consideration, with a view toward balancing the technology's benefits against the resources and expertise it demands.
Managing Complexity with Multiple Private LLMs
The shift towards utilizing multiple Large Language Models (LLMs) to boost performance introduces significant complexities, especially when these systems are maintained in private cloud environments. Operating several LLMs simultaneously amplifies the demand for processing power, memory, and storage—each model adding to the infrastructure load and increasing operational costs substantially. Checkout our detailed webinar on Data Loss Prevention in LLM like ChatGPT.
Coordinating these resources to ensure that each LLM functions efficiently without resource conflicts presents a formidable challenge in system management. Moreover, the varied needs for updates, the specific vulnerabilities, and the distinct dependencies of each model require diverse technical skills and precise coordination.
This scenario underscores the necessity for detailed resource planning and technical agility to handle the heightened requirements of running multiple LLMs effectively.
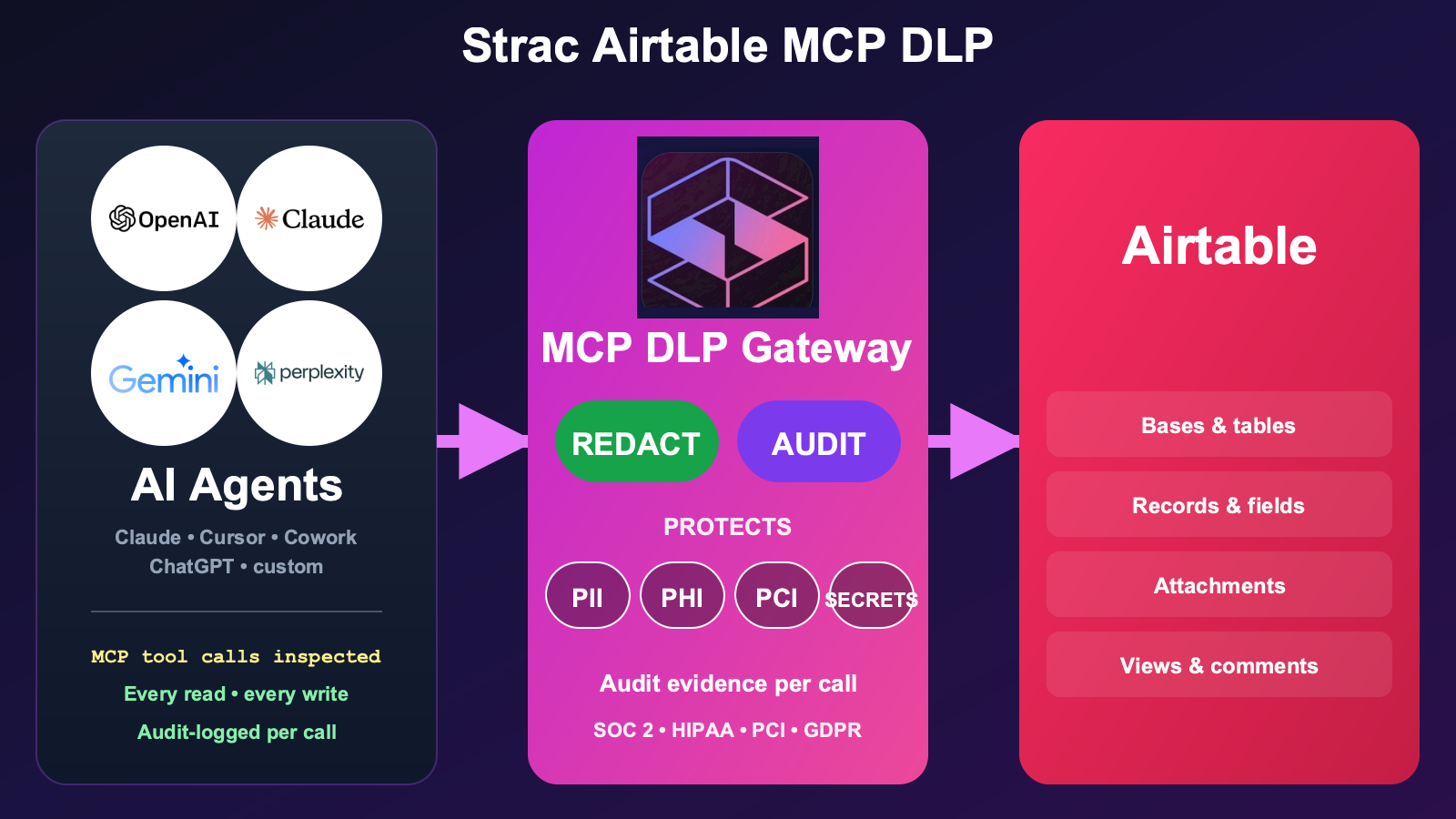
How Strac Protects Sensitive Data in Any LLM?
Strac's approach to securing data within Large Language Models (LLMs) employs advanced Data Loss Prevention (DLP) technologies tailored to safeguard sensitive information regardless of the LLM's deployment environment. Here's how Strac integrates these technologies into LLMs and a breakdown of their key features:
Integration of Strac DLP with LLMs
Strac’s DLP solutions are designed to seamlessly integrate with any LLM, ensuring that data privacy and security are maintained throughout the data lifecycle. This integration typically involves the implementation of Strac's tools at various stages of data processing and model training, from initial data collection to the output generation phase of an LLM. By embedding DLP capabilities directly into the LLM workflow, Strac ensures that all sensitive data handled by the model is continuously protected against unauthorized access and leaks.
Key Features of Strac DLP
Real-Time Data Monitoring and detection: Strac’s DLP system includes dynamic data masking capabilities, which automatically obscure sensitive data elements in real time as they are processed by the LLM. This means that sensitive information such as personal identifiers or confidential business information can be protected from exposure, even during live interactions with the model.
Strac DLP sensitive data detection classification and redaction in slack
Redaction: Strac’s DLP also features sophisticated redaction tools that permanently remove or obscure specific data elements within a dataset before it is used by an LLM. This is particularly useful in contexts where complete data removal is necessary to comply with legal requirements or to mitigate the risk of sensitive data exposure.
Together, these features form a comprehensive security framework that not only protects sensitive data but also enhances the overall trustworthiness and reliability of LLM applications. By implementing Strac’s DLP solutions, organizations can confidently deploy LLM technologies, knowing that their data is secure and their compliance obligations are met.
Conclusion
Private Large Language Models (LLMs) represent a significant advancement in the field of artificial intelligence, particularly in enhancing data privacy standards. By isolating models within a controlled environment, private LLMs inherently reduce the risks associated with widespread data access and leaks prevalent in more open systems. This privacy-by-design approach is crucial for industries handling sensitive information, where data breaches can have severe consequences.
However, the privacy capabilities of private LLMs are not foolproof. Advanced-Data Loss Prevention (DLP) solutions like Strac play a pivotal role in shoring up these defenses. Strac's comprehensive suite of DLP tools—including real-time data masking, encryption, and redaction—addresses critical vulnerabilities, ensuring that data remains protected across all stages of interaction with LLMs. By integrating such robust security measures, organizations can enhance the efficacy and trustworthiness of their LLM deployments, meeting both regulatory requirements and ethical standards.
To truly understand how Strac can fortify your private LLMs against emerging threats and privacy challenges, consider scheduling a demo. This hands-on experience will provide a deeper insight into how Strac’s technologies can safeguard your critical data assets.
Discover & Protect Data on SaaS, Cloud, Generative AI
Strac provides end-to-end data loss prevention for all SaaS and Cloud apps. Integrate in under 10 minutes and experience the benefits of live DLP scanning, live redaction, and a fortified SaaS environment.

.webp)
.png)














.gif)
