Data Classification Matrix: The Foundation of Modern Data Governance
A data classification matrix helps organisations categorise data by sensitivity, risk, and required controls to strengthen compliance and prevent breaches. Learn how to build, automate, and maintain a data classification matrix with Strac to protect sensitive data across SaaS, cloud, and AI environments.
A data classification matrix is a structured framework that categorises data by sensitivity, risk, and required protection controls. It enables consistent data governance across SaaS, cloud, and AI systems while ensuring regulatory compliance and reducing the risk of breaches.
A data classification matrix maps data types (e.g., PII, PHI, financial data) to levels such as Public, Internal, Confidential, and Restricted for uniform handling.
It supports compliance with GDPR, HIPAA, PCI DSS, and ISO 27001 by defining how each category of data must be stored, accessed, and secured.
Best practices include keeping levels simple, aligning them with business risk, assigning ownership, and reviewing classifications regularly.
Automating classification with Strac enables continuous discovery, labelling, and protection of sensitive data across SaaS and cloud environments.
Implementing a data classification matrix with Strac helps organisations minimise unclassified data, improve visibility, and streamline audit readiness.
Today, more than ever, the importance of a well-defined data classification matrix cannot be overstated. With growing data volumes, rapid SaaS and cloud expansion, and tightening regulations like GDPR, HIPAA, and PCI DSS, businesses face increasing pressure to know what data they have, where it lives, and how it’s protected. A strong data classification matrix helps organisations identify sensitive information, assign the right security controls, and maintain compliance across complex, distributed environments. Misclassified or unclassified data often leads to breaches, fines, or reputational damage; costs that most companies cannot afford.
This guide walks you through everything you need to know about creating and maintaining a data classification matrix. You’ll learn what it is, why it matters, and how to build one step by step. We’ll explore real-world use cases, best practices, and common pitfalls, along with how Strac's agentless DSPM + DLP platform automates discovery, classification, and remediation across SaaS, cloud, and GenAI environments; making data protection simpler, faster, and smarter.
✨What Is a Data Classification Matrix?
Adata classification matrix is one of the most fundamental tools in information security and compliance management. It provides a structured way for organisations to map their data according to risk, sensitivity, and required controls. By defining how each data type should be handled across its lifecycle, a data classification matrix ensures consistency, accountability, and protection in every corner of the business. This section explores the concept in detail, explains why it matters, and outlines the most common data classification levels and labels used by modern enterprises.
Definition & Key Dimensions
A data classification matrix is a visual grid that enables organisations to categorise their data assets according to importance, risk, and compliance needs. Typically, one axis lists data types such as customer records, financial documents, intellectual property, or system logs; the other axis lists classification levels such as Public, Internal, Confidential, and Restricted. The intersection between these two axes defines what policies and controls apply to each data category, from storage and access permissions to encryption and retention.
Classification within the matrix also aligns closely with the CIA triad; confidentiality, integrity, and availability. Each classification level reflects how the organisation should balance these three principles. For example, “Restricted” data demands the highest level of confidentiality and integrity, while “Public” data prioritises availability. By applying this framework consistently, organisations strengthen their data security posture and prevent costly data mishandling or loss.
Strac Data Classification
Why Data Classification Matrix Matters
A well-designed data classification matrix is more than a compliance checkbox; it’s a risk mitigation engine for the entire organisation. It aligns protective controls with data value and risk exposure, ensuring that every file, dataset, or message is treated according to its sensitivity. This prevents overspending on low-risk data while reducing the likelihood of breaches in high-risk areas.
Regulatory compliance is another critical driver. Frameworks like GDPR, HIPAA, and ISO 27001 require companies to identify and categorise personal or regulated information before applying protection measures. Even academic institutions and government entities rely on their own data classification matrices, such as the University of Iowa or UCF models, to standardise governance and auditing.
Beyond compliance, a data classification matrix also improves operational efficiency. It streamlines access management, storage optimisation, and data retention while preventing overexposure of internal data. In the modern SaaS and AI era, this matrix becomes even more vital; classification ensures sensitive data is never used to train large language models, shared through unsecured APIs, or synced to unapproved cloud tools.
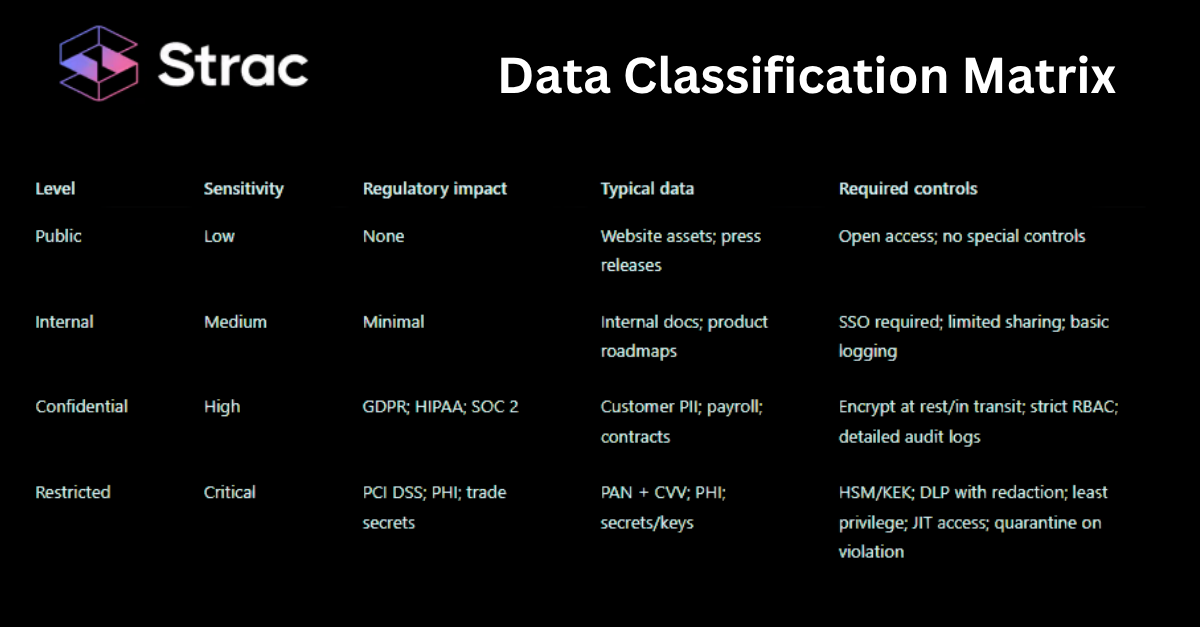
✨Common Classification Levels & Labels
To make a data classification matrix practical, companies typically define a clear set of classification levels that reflect sensitivity and risk. Each level outlines who can access the data, how it can be shared, and what protection measures are mandatory. Maintaining a simple but comprehensive hierarchy ensures clarity across departments, especially in large organisations with multiple data sources and systems.
Below are the four most common data classification levels used by enterprises worldwide:
Public / Unrestricted: Data intended for open access, such as press releases or marketing collateral.
Internal Use: Data limited to employees or approved partners, like training materials or operational procedures.
Confidential: Sensitive information such as customer PII, financial statements, or contracts that requires encryption and controlled access.
Highly Confidential / Restricted: Critical assets including PHI, trade secrets, API keys, or encryption certificates requiring the highest protection.
Having too many levels creates confusion and slows decision-making; too few can lead to under-protection. Most mature organisations find four to five tiers optimal for balancing security and usabilit
Data Classification Matrix Levels and Labels
This data classification matrix example highlights how different data categories align with specific protection levels. Once defined, these classifications can be enforced automatically through tools like Strac, ensuring real-time detection, labelling, and remediation.
✨How to Create a Data Classification Matrix (Step-by-Step)
A data classification matrix becomes powerful when it is built methodically; scoped correctly; and embedded into daily workflows. This step-by-step guide summarises what you will do; first you will inventory systems and data; next you will define clear classification levels and criteria; then you will map assets to levels; assign owners; attach concrete controls; automate with tooling; and set a cadence to review and improve. In the detailed sections below, you will see practical examples, a sample criteria table, and a populated matrix so your data classification matrix moves from theory to action inside your SaaS and cloud estate.
Step 1 – Define your scope & data inventory
A data classification matrix starts with a complete, trustworthy inventory; you cannot classify what you cannot see. Capture systems across on-prem, cloud, and SaaS; include APIs, shared drives, email, chat, tickets, data warehouses, and AI tools. For each source, list data types; storage locations; integrations; and name an accountable team so the matrix has owners from day one.
Identify systems and locations: on-prem databases; cloud storage; collaboration tools; ticketing; CRM; code repos; data warehouses; GenAI tools.
Map owners and stakeholders: business owner; data steward; security; privacy; compliance; IT operations.
Step 2 – Define classification levels & criteria
Your data classification matrix needs clear, consistent levels so teams apply the same judgement every time. Most organisations succeed with 3–5 levels; keep names intuitive; and define criteria that reflect business value, regulatory impact, and handling rules. This gives you defensible decisions during audits and a shared language across security, legal, and engineering.
Choose levels: typically Public; Internal; Confidential; Restricted; optionally add Highly Restricted for crown jewels.
Define criteria per level: sensitivity; legal and regulatory exposure; business criticality; retention; access restrictions; encryption; monitoring.
Document examples: real records and fields per level so teams classify by pattern and precedent; not guesswork.
Example criteria table
A short table helps operationalise your data classification matrix; it turns abstract labels into concrete handling rules that anyone can follow.
Data Classification Matrix
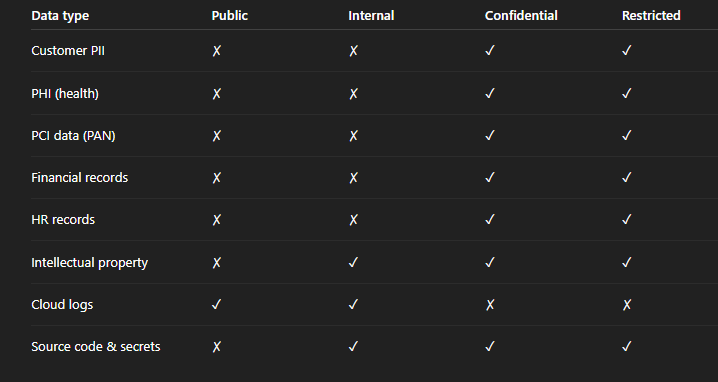
Step 3 – Map data types/assets → classification
This is where your data classification matrix becomes real; you cross-tabulate data types against levels and mark the minimum required level for each. Start with high-risk categories; then work down to ancillary data; and validate with legal and compliance to ensure coverage aligns with obligations. The outcome is a populated grid you can enforce through policy and tooling.
Build the grid from your inventory: rows are data types; columns are levels.
Mark the minimum acceptable level; add notes for exceptions; and link to systems where that data resides.
Pilot the matrix on a few SaaS apps; refine wording; then publish and train.
Sample populated matrix
Before the table, remember that this sample is a starting point; adapt it to your industry, data flows, and risk appetite so your data classification matrix reflects reality.
Data Classification Matrix
Step 4 – Assign data owners & stewardship roles
Ownership turns a data classification matrix from a static document into a living control system; every row needs someone accountable. Define the data owner who decides classification and access; the data steward who executes day-to-day tasks; and the reviewers who sign off changes. Tie this directly to RBAC and access governance so permissions flow from classification; not convenience.
Assign an accountable Data Owner per category; usually the business function that creates or relies on the data.
Name a Data Steward; usually operations or IT; to maintain labels; respond to alerts; and coordinate remediation.
Integrate with access governance; approvals; and periodic access reviews tied to classification level.
Step 5 – Define controls for each classification
Controls translate your data classification matrix into concrete safeguards; each level should prescribe storage, encryption, access, monitoring, sharing, and retention. Write controls in plain language so product and ops teams can implement them; add examples; and include redaction or masking rules for high-sensitivity flows like chat; tickets; and GenAI.
Public: company systems allowed; no sensitive content; optional checksum or integrity checks for downloads.
Confidential: encryption in transit/at rest; strict RBAC; DLP inspection; watermarking; 1–3 year retention; audit trails.
Restricted: HSM-backed keys; tokenisation or redaction at ingress; zero trust access; continuous monitoring; least privilege; JIT access; short retention and defensible deletion.
🎥Step 6 – Implement tooling and automation
Automation is how your data classification matrix scales across SaaS; cloud; endpoints; and AI. Integrate discovery; DLP; and DSPM so labels are applied consistently; exposures are remediated in real time; and reports are always audit-ready. Strac helps by scanning text; files; and attachments; applying labels; redacting sensitive content in chat and tickets; and generating compliance dashboards your auditors will accept.
Connect SaaS and cloud sources; enable continuous scans for sensitive entities.
Auto-label findings; sync labels to storage and collaboration tools; and enforce DLP policies from the matrix.
Use dashboards; alerts; and webhooks to orchestrate remediation; quarantine; or coach users at the point of action.
Step 7 – Review, audit & evolve the matrix
A data classification matrix is never finished; data flows change; risks evolve; new regulations arrive. Put your matrix on a schedule; run quarterly reviews keyed to audits; and track exceptions so you can show improvement over time. Use metrics such as percentage of unclassified data; number of exposures per month; and time-to-remediate to prove control maturity.
Schedule periodic reviews; update criteria; levels; and examples as products and laws change.
Use audit trails; exception registers; and evidence packs to streamline compliance.
Report KPIs: coverage of classified data; reduction in exposures; audit hours saved; policy adherence.
Best Practices & Pitfalls to Avoid
Creating a data classification matrix is only the first step; keeping it accurate, consistent, and practical is where long-term value lies. A successful matrix should guide decision-making, compliance, and day-to-day data handling across departments. When designed with simplicity, ownership, automation, and regular updates in mind, it becomes a living framework that continuously strengthens data protection and compliance posture. Below are the best practices and pitfalls every organisation should keep in mind when building and maintaining their data classification matrix.
A strong data classification matrix works best when it’s intuitive. Keep it simple; too many classification levels confuse employees, slow decision-making, and create inconsistencies in data handling. Most organisations achieve the best balance with four or five levels that map cleanly to risk and data value.
Keep it simple: Avoid unnecessary complexity; clarity drives adoption.
Assign ownership: Ensure every data category and control has an accountable owner.
Align with business value: Classifications must mirror real business impact, not IT labels.
Automate wherever possible: Integrate DSPM and DLP tools to auto-label, detect, and remediate data exposures.
Break silos: Connect classification with privacy, data governance, and access management functions for a unified view.
Educate employees: Train users to understand what each level means and how to apply it in daily workflows.
Review regularly: Update your matrix every quarter or after major organisational or regulatory changes.
Ignoring best practices can undermine the effectiveness of a data classification matrix and expose your organisation to unnecessary risk. The most common pitfalls occur when teams overcomplicate structures, fail to maintain ownership, or neglect new data surfaces introduced by cloud and SaaS tools. Equally dangerous is not reviewing or updating the matrix, which can leave sensitive data unprotected and compliance audits incomplete.
Neglecting SaaS and spreadsheets: Sensitive data often hides in SaaS chats, spreadsheets, and attachments that remain unclassified.
Skipping deletion and retention: Without proper lifecycle management, data accumulates, increasing breach and compliance risk.
Mis-mapping controls: Applying weak controls to high-risk data; or over-restricting harmless data; creates friction and inefficiency.
Over-engineering: Building overly complex matrices that employees can’t follow reduces adoption and usability.
🎥 Data Classification Use Cases & Examples
A data classification matrix delivers real-world impact when applied across everyday business scenarios; it transforms how organisations govern data, manage risk, and prove compliance. Whether you’re handling SaaS sprawl, migrating to the cloud, integrating GenAI tools, or preparing for audits, this framework ensures sensitive data is never misplaced or mishandled. The following use cases demonstrate how companies leverage their data classification matrix to strengthen governance, streamline operations, and automate security through platforms like Strac.
Use Case 1: SaaS Application Data Governance
Modern organisations depend on dozens of SaaS apps; from Slack and Salesforce to Jira and Intercom; each holding fragments of sensitive data. Without visibility, confidential data can easily reside in unsecured systems or user uploads. A data classification matrix helps map which applications handle Confidential or Restricted data, apply the right access rules, and set clear handling boundaries.
By integrating with platforms like Strac , security teams can automatically analyse SaaS logs, discover unclassified files or conversations, and apply the correct sensitivity labels in real time. This ensures every message, attachment, or ticket containing customer PII, PCI, or PHI is redacted, masked, or blocked instantly; preventing leaks before they occur.
Identify SaaS tools with sensitive data exposure (e.g., Slack, Zendesk, Salesforce).
Classify each based on the data they process (Public, Internal, Confidential, Restricted).
Apply automated remediation and access controls to enforce compliance policies.
✨Use Case 2: Cloud Migration & Retention Optimisation
A well-defined data classification matrix guides cloud migration decisions by helping organisations determine which data should move, which to archive, and which to delete securely. When transitioning large data repositories, applying classification first avoids moving redundant or high-risk data unnecessarily. This saves storage costs, simplifies compliance, and reduces cloud attack surfaces.
For instance, Public or Internal files can be migrated easily to standard storage; Confidential or Restricted records should undergo encryption, access validation, and potentially masking before migration. Teams can also use Strac scanning capabilities to classify files in bulk, apply encryption policies automatically, and generate retention schedules based on sensitivity.
Categorise on-prem data assets by sensitivity level before migration.
Archive or delete low-value Internal data to reduce storage footprint.
Encrypt or tokenise Restricted data before uploading to cloud repositories.
Strac Data Classification Advanced Access
✨Use Case 3: Generative AI Risk Management
Generative AI tools such as ChatGPT, Copilot, and Bard have introduced new data exposure risks; sensitive data can unintentionally feed into prompts or training sets. A data classification matrix defines which data categories are safe for AI processing and which are strictly prohibited. For example, Restricted datasets like PHI or financial identifiers should never be used in AI inputs, while Internal datasets may be safely anonymised.
Legal experts such as Michalsons emphasise that a data classification framework is vital to manage data governance in AI workflows. By using Strac's GenAI integration, companies can automatically detect when sensitive text or files are about to be sent to AI systems, block the transmission, or redact risky content. This ensures innovation continues safely without breaching compliance.
Tag AI-approved and AI-restricted datasets clearly in the matrix.
Use Strac to intercept sensitive prompts or outputs automatically.
Generate audit logs showing compliance with AI usage policies.
Strac Browser GenAI Data Classification and Remediation
✨Use Case 4: Audit-Ready Compliance & Reporting
Compliance audits often require proof of how sensitive data is classified, where it resides, and which controls apply. A data classification matrix acts as the single source of truth; it documents classifications, owners, applied controls, and remediation actions. This transparency builds trust with auditors, regulators, and internal stakeholders while reducing preparation time.
Strac enhances this process by providing audit-ready dashboards and reports that show classification coverage, access violations, and resolved exposures. The system continuously logs classification changes and policy enforcement, creating evidence trails auditors can review instantly.
Export your data classification matrix as a compliance report for HIPAA, GDPR, or PCI DSS.
Demonstrate coverage metrics and reduction of unclassified data over time.
Use Strac's automated reporting to save hundreds of hours in audit preparation.
Together, these examples illustrate how a data classification matrix becomes the operational core of governance and compliance. When paired with Strac it evolves from a static spreadsheet into a dynamic, automated safeguard across SaaS, cloud, and GenAI environments; turning visibility into proactive protection.
Strac Reporting on Data Classification
✨How Strac Supports Your Data Classification Matrix
A data classification matrix becomes exponentially more powerful when supported by intelligent automation. Manual tracking in spreadsheets or static tools can’t keep up with the velocity of data moving through SaaS platforms, cloud repositories, and AI workflows. That’s where Strac transforms the process; it continuously discovers data across your ecosystem, applies classification labels in real time, and enforces protection policies automatically. With its unified DSPM + DLP architecture, Strac provides complete visibility, precise control, and measurable compliance outcomes for your entire organisation.
Feature Overview
Strac combines data discovery, posture management, and prevention into one seamless system. It automatically scans both structured and unstructured data across SaaS, cloud, endpoints, and GenAI tools; applying classification labels based on content, context, and risk. The platform uses advanced ML + OCR detection; far more accurate than regex; to identify sensitive information such as PII, PHI, PCI, or source code embedded in files, messages, or databases.
Within a few minutes of deployment, Strac delivers:
Automated discovery of sensitive data across connected apps and storage locations.
Classification labelling that aligns directly with your data classification matrix levels (Public, Internal, Confidential, Restricted).
Built-in dashboards and reporting that visualise classified data, violations, and remediation actions.
Role-based access controls (RBAC) ensuring the right people have the right level of visibility.
Seamless integration with DLP and EDM policies to enforce encryption, redaction, and blocking in real time.
Use Case Alignment
The real power of Strac lies in how it aligns directly with the four use cases discussed above; ensuring the data classification matrix doesn’t just exist on paper, but functions automatically across all workflows.
SaaS Application Governance: Strac connects with Slack, Zendesk, Salesforce, Google Workspace, and dozens more to scan messages, attachments, and tickets. It redacts PII, PHI, and PCI data instantly; keeping SaaS environments compliant and secure.
Cloud Migration & Retention Optimisation: During migration, Strac analyses files in bulk, classifies them, and recommends encryption or deletion policies.
Generative AI Risk Management: Strac integrates with ChatGPT, Copilot, and Bard APIs; automatically detecting and blocking sensitive information before it reaches AI models.
Audit-Ready Compliance: Built-in reporting tracks classification coverage, open violations, and resolved incidents; creating defensible audit evidence for frameworks like GDPR, HIPAA, and PCI DSS.
Strac Full Integrations
Ready to see how Strac can modernise your data classification matrix? Request a short walkthrough to explore how automation can help your team classify once and protect everywhere; across SaaS, cloud, and AI environments.
Data Classification Matrix Checklist
Operationalising your data classification matrix requires a clear checklist that ensures every foundational step is complete. Following this sequence helps your team maintain coverage, reduce unclassified data, and ensure continuous alignment with evolving regulations.
Before the checklist, remember that the keyword “data classification matrix” should remain central to every task; this guarantees your controls and automation reflect the exact sensitivity levels defined in the matrix itself.
✅ Operational Checklist for Data Classification Matrix Implementation:
Scope defined: Identify all systems, data sources, and SaaS applications included in the classification process.
Classification levels defined: Establish consistent sensitivity tiers such as Public, Internal, Confidential, and Restricted.
Data inventory completed: Catalogue data assets and link them to owners, storage systems, and access controls.
Roles assigned: Appoint data owners and stewards responsible for maintaining classifications and reviewing access.
Controls mapped: Link each classification level to its required encryption, storage, and monitoring controls.
Tooling integrated: Connect automation platforms like Strac to continuously discover, label, and remediate sensitive data.
Review schedule set: Establish quarterly or biannual reviews to refresh classifications, validate access, and close gaps.
Bottm Line
A data classification matrix is not just a compliance exercise; it is the foundation of secure and intelligent data governance. By mapping every data type to its sensitivity level, organisations gain full visibility into where sensitive information lives, who can access it, and how it should be protected. This structured approach strengthens compliance with GDPR, HIPAA, PCI DSS, and ISO 27001, reduces the risk of data leaks, and improves operational efficiency across SaaS and cloud systems.
With automation through Strac, your data classification matrix evolves continuously; scanning, labelling, and protecting data in real time across every app and storage location. The result is fewer manual errors, faster audits, and a stronger security posture. When implemented effectively, a data classification matrix allows you to classify once and protect everywhere; ensuring your organisation remains compliant, efficient, and resilient in the face of modern data risks.
🌶️Spicy FAQs on Data Classification Matrix
What is a data classification matrix and why does it matter?
A data classification matrix is a structured grid that helps organisations categorise information based on its sensitivity, risk, and required protection controls. Think of it as a map that connects data types (like customer PII, HR records, and contracts) with security levels (Public, Internal, Confidential, Restricted). Each cell defines how that data must be stored, shared, encrypted, and retained.
Beyond compliance, a data classification matrix ensures business efficiency. It prevents teams from overspending on low-risk data and safeguards critical assets that could trigger costly fines or breaches if mishandled. When managed dynamically, especially through automation, it becomes a cornerstone of your company’s data governance strategy.
How do I create a data classification matrix for my organisation?
Building a data classification matrix starts with understanding your data landscape. Identify all systems, apps, and repositories; then categorise every data type according to sensitivity and business impact. Define 3–5 levels; keeping them simple but actionable; and assign owners and stewards to ensure accountability.
Next, create control mappings for each level, such as encryption standards, retention periods, and access requirements. Finally, embed these policies into your DLP or DSPM tools so classifications stay current without manual effort. Using Strac, this process becomes continuous; the platform scans and labels data automatically across SaaS, cloud, and AI environments, providing real-time visibility and remediation.
What are the best practices for maintaining a data classification matrix?
Maintaining a strong data classification matrix means turning it from a one-time exercise into a living, evolving framework that grows with your business. Start by keeping the structure simple, no more than four or five levels, so employees can easily apply it. Align every level with clear business value and compliance risk, ensuring that controls like encryption, access limits, and retention rules match sensitivity. Assign data owners to maintain accountability; use automation to eliminate manual errors; and schedule regular reviews to keep everything up to date as regulations and systems evolve.
Keep it simple: Avoid unnecessary complexity; fewer levels increase usability and accuracy.
Align with real risk: Match classification levels to actual data sensitivity and business impact.
Assign ownership: Give each data category a defined owner and steward for accountability.
Automate classification: Use tools like Strac to label, detect, and remediate sensitive data automatically.
Educate continuously: Train employees so classification becomes second nature across all workflows.
Review and refine: Revisit classifications quarterly to ensure ongoing compliance and relevance.
By applying these best practices, your data classification matrix remains accurate, scalable, and impactful. It empowers teams to make smarter security decisions, reduces audit fatigue, and ensures every byte of sensitive data is properly managed; no matter where it lives across SaaS, cloud, or AI ecosystems.
Discover & Protect Data on SaaS, Cloud, Generative AI
Strac provides end-to-end data loss prevention for all SaaS and Cloud apps. Integrate in under 10 minutes and experience the benefits of live DLP scanning, live redaction, and a fortified SaaS environment.

.webp)


















.gif)
