June 28, 2026
7
min read
Google Drive Data Classification: What It Is, Why It Matters, and How to Do It Right
Google Drive Data Classification: How to Identify & Protect Sensitive Files
.webp)
Google Drive Data Classification: How to Identify & Protect Sensitive Files

As more organizations rely on Google Drive for collaboration and storage, the risk of storing unclassified or sensitive data in the wrong place has never been higher. From confidential contracts to customer PII buried in spreadsheets, the consequences of a single file being mishandled can be severe; think compliance violations, insider threats, or data leaks.
That’s where Google Drive data classification steps in.
In this post, we’ll explore what Google Drive data classification is, why it’s essential, what an ideal solution looks like, and how Strac helps protect sensitive data with automation, remediation, and compliance readiness.
Google Drive data classification refers to the process of identifying, labeling, and categorizing files stored in Google Drive based on their sensitivity — including PII, PHI, payment data, or internal IP. Classification enables organizations to apply policies that secure files, limit access, and comply with regulations.
If you’re managing sensitive files within the Google Workspace ecosystem, Google Drive data classification helps ensure documents don’t become compliance liabilities or get shared beyond intended boundaries.
Google Workspace offers built-in classification labels through the Admin Console. Here's what you get:
This is why organizations need automated classification that scans file contents, not just metadata.
Strac Google Drive Labels make native Google Drive labels actually useful. Strac applies and manages Google’s own labels directly, keeping them consistent with no duplicate labeling and no manual effort.
Instead of relying on users to tag files, Strac automatically discovers sensitive data in Google Drive and labels it based on real content and context. This works across documents, PDFs, spreadsheets, and uploads, even as files change, move, or get reshared.
Those labels are not passive. They actively drive protection:
The result is continuous visibility and enforcement, without slowing down how teams actually work in Google Drive.
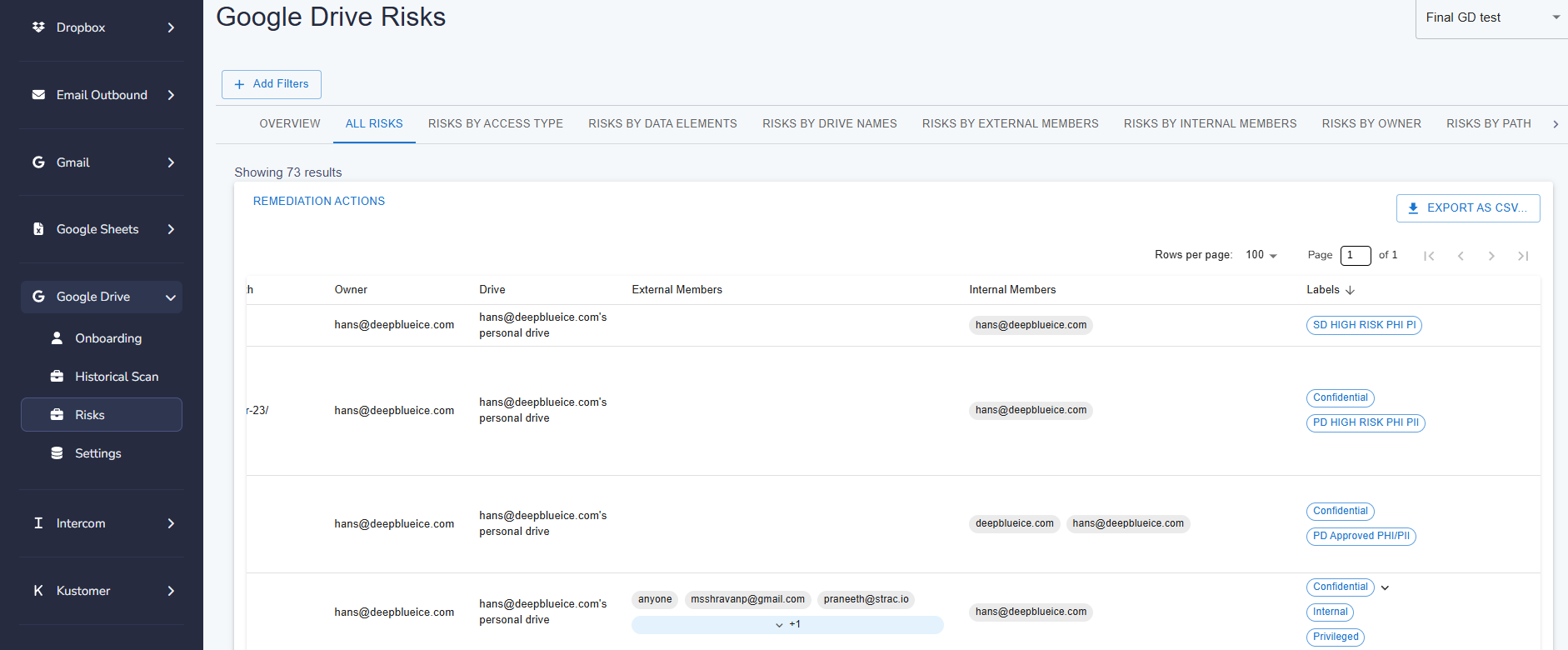
To understand why automation matters, it helps to compare the different ways teams classify data in Google Drive and how they trade off accuracy, effort, and scale.
| Manual labeling | Low accuracy due to human error; high effort required; best suited for very small teams with low file volume. |
| Default Drive labels | Medium accuracy with low effort; useful for setting baseline classification policies without deep inspection. |
| Google DLP rules | Medium accuracy with moderate setup effort; relies on keyword and pattern matching for basic controls. |
| AI-powered (Strac) | High accuracy with no manual effort; automatically detects and classifies PII and PHI at scale across Google Drive. |
Strac automates this classification using ML and OCR, surfacing risks across every Drive folder — even inside screenshots, images, and archived content.

The file includes emails and phone numbers. A good classification system detects this PII and tags the document as “Confidential – PII,” triggering access restrictions and alerts.
Classification tags it as “Restricted – PCI Data,” ensuring it's encrypted and cannot be shared externally.
The classification engine identifies it as “Sensitive – PHI” and blocks unauthorized users from accessing or downloading it.
Strac’s platform automatically classifies this kind of content using sensitive data discovery and classification powered by machine learning and OCR.
Google Drive, while powerful and widely used, wasn’t designed with advanced enterprise-level data security in mind. Without classification, organizations face a number of serious risks:

Employees may unknowingly share sensitive documents with external users or across departments.
Example: An intern mistakenly shares a customer invoice folder (containing addresses and payment details) with a personal Gmail account.
When files are not labeled or restricted, even well-meaning employees can mishandle data.
Example: A developer downloads a document with access keys and uploads it to a public repo.
Failure to identify and manage sensitive data can lead to hefty fines under HIPAA, PCI DSS, GDPR, and more.
Example: A healthcare organization fails an audit due to unclassified PHI documents stored in Google Drive.
For a deeper breakdown on how we help organizations avoid these risks, check out our Google Drive DLP overview.
Without automated data classification in Google Drive, organizations are exposed to a range of risks that can result in financial penalties, legal issues, and reputational damage.
Employees often upload and share files without realizing the content contains sensitive or regulated information. Google Drive data classification helps flag these files in real time.
Unclassified data can be easily mishandled — downloaded to personal devices, emailed externally, or moved to unauthorized locations.
Standards like HIPAA, GDPR, CCPA, PCI DSS, and ISO 27001 require organizations to implement controls to detect, label, and protect sensitive data. Google Drive data classification is a foundational step in achieving compliance.
Want to see how Strac’s Google Drive DLP solution helps prevent these issues? We’ve built it to be real-time, customizable, and audit-ready.

1. Go to Admin Console → Apps → Google Workspace → Drive
2. Enable Labels under "Classification"
3. Create label taxonomy (Public, Internal, Confidential, Restricted)
4. Set default label for new files
5. Create DLP rules based on labels
1. Connect Google Workspace (OAuth, 5 minutes)
2. Choose detection templates (PII, PHI, PCI, custom)
3. Set policies (alert, label, redact, quarantine)
4. Review discovered sensitive files in dashboard
5. Enable real-time scanning for new uploads
When evaluating solutions for Google Drive data classification, here are the must-haves:

The solution should automatically scan every file, folder, and format — including PDFs, images (OCR), ZIP files, and more.
Detection across both shared and personal drives is key.
Strac automates this process, surfacing risk in seconds.

Out-of-the-box detectors for PII, PCI, PHI, financial data, credentials, and source code.
Ability to define custom classifiers for industry-specific or internal data types.

View the full Strac catalog of sensitive data elements.
Modern classification systems must go beyond keyword matching. ML-based analysis plus OCR ensures sensitive data in screenshots or scanned documents isn’t missed.
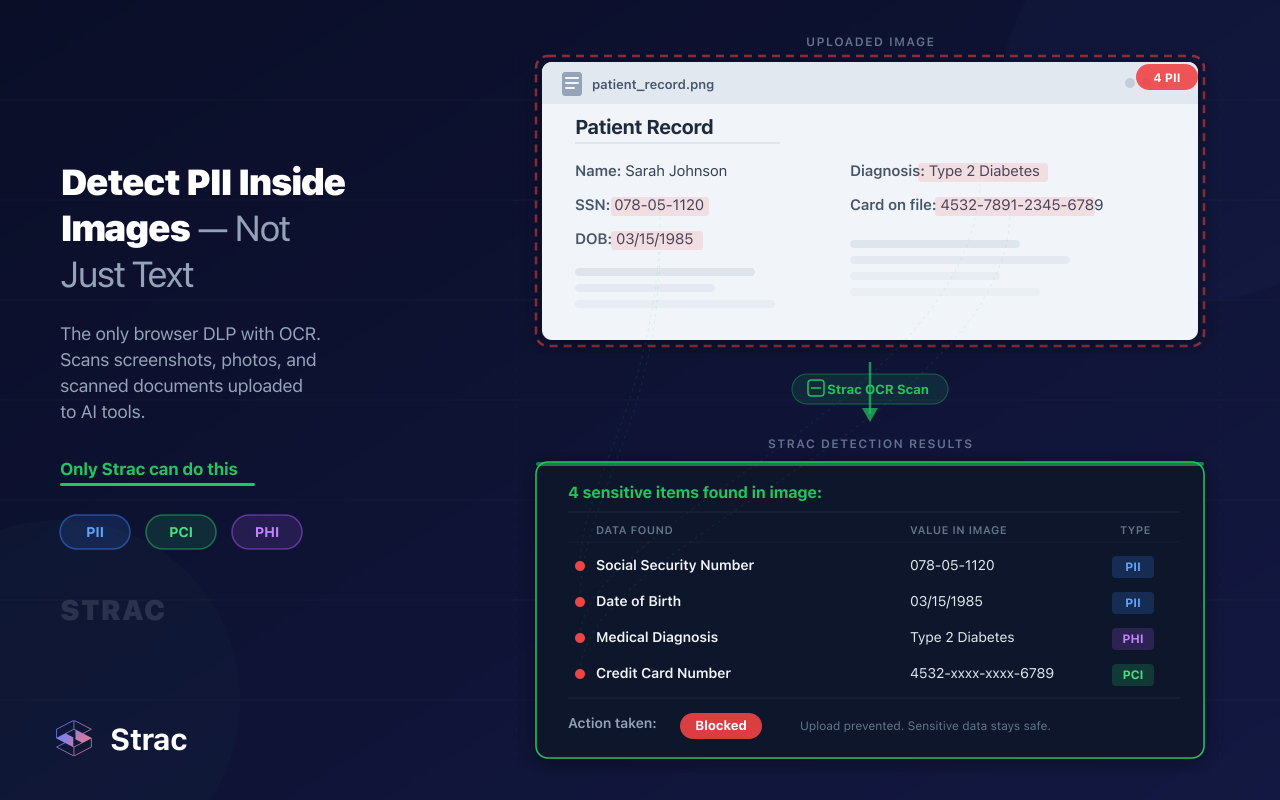
Strac’s ML-powered classification gives teams full visibility into all file types.
Tags like “Confidential,” “Internal,” “Restricted,” or “Public” should be dynamically applied based on policies.
Should trigger remediation: blocking, alerting, redacting, encrypting, or deleting as needed.

Learn more about Strac’s remediation playbook.
Classification should not be a silo. It should drive DLP actions and feed compliance dashboards.
Strac makes it simple to integrate across your SaaS, cloud, and endpoint tools in under 10 minutes.
The next phase of Google Drive data classification is defined by automation, intelligence, and interoperability. As cloud ecosystems expand and organizations generate massive amounts of unstructured data daily, traditional rule-based classification cannot keep up. The future will belong to solutions that combine machine learning (ML), artificial intelligence (AI), and predictive analytics to continuously detect, classify, and secure sensitive data; without human intervention or manual tagging.
AI is revolutionizing the way Google Drive data is analyzed and secured. Unlike regex-based detection, AI-driven classification uses contextual understanding, natural language processing (NLP), and OCR to identify sensitive information even in complex or unstructured formats. Whether it’s a screenshot containing a social security number or a spreadsheet with financial data, AI-powered systems like Strac detect it instantly. This intelligence enables real-time labeling and remediation, ensuring sensitive data never slips through undetected. Over time, these models learn from user feedback to continuously refine accuracy and reduce false positives.
The future of data classification will not be siloed. As organizations adopt multi-cloud environments, seamless integration between Google Drive, OneDrive, Box, and Dropbox will become critical. Businesses will need unified visibility across all repositories to apply consistent security and compliance policies. Strac already leads this shift by offering agentless coverage across 40+ integrations, including Google Workspace, Slack, Salesforce, and AWS. This cross-platform orchestration helps eliminate blind spots, ensuring sensitive data remains protected no matter where it’s stored or shared.
Predictive classification is emerging as a game-changer. Instead of reacting to data exposure, future systems will predict risks before they occur; dentifying likely data leaks, access anomalies, or policy violations based on behavioral patterns. For example, Strac’s predictive models can flag files that are likely to contain regulated data (like PII or PHI) even before they are fully scanned, accelerating remediation and compliance actions. These capabilities will evolve into proactive defense mechanisms, enabling organizations to stay ahead of both internal and external threats while maintaining compliance effortlessly.
The future of Google Drive data classification will move beyond labeling; it will be about anticipation, orchestration, and real-time defense. Platforms like Strac are setting this standard by combining AI, predictive analytics, and multi-cloud visibility to keep sensitive data protected from creation to collaboration.
At Strac, we’ve built a modern DSPM + DLP platform that doesn’t just classify your Google Drive data — it gives you real-time visibility, protection, and control.

Strac uses advanced ML and OCR to scan and classify sensitive data in any format: PDFs, screenshots, chat exports, email bodies, cloud databases, ZIPs, spreadsheets — you name it.
Explore our discovery and classification capabilities.
Support for all major data types: PCI, HIPAA, GDPR, credentials, secrets, and even custom types you define.
Explore our sensitive data catalog.
Strac’s machine learning models classify files based on your policies, tagging them with labels like “PHI,” “Internal,” “Sensitive,” etc., and flagging them for remediation.
We’re the only DSPM + DLP solution with built-in actions like:
Strac integrates quickly with Google Drive, Gmail, Slack, Jira, and more.
Browse all available integrations to protect every layer of your environment.

Strac helps you maintain compliance with frameworks like PCI DSS, HIPAA, SOC 2, GDPR, and ISO 27001.
Our compliance-ready architecture ensures your classification program supports audit and regulatory readiness.
Don’t just take our word for it. See what our customers have to say by browsing Strac reviews on G2.
The future of Google Drive data classification is intelligent, predictive, and unified. As data volume and complexity continue to grow, businesses will depend on AI-powered systems that can automatically discover, classify, and secure sensitive information across every file and folder. Manual tagging or regex rules will no longer be enough; continuous ML-driven classification with real-time remediation will become the new baseline for compliance and security. Strac is already leading this transformation by combining agentless DSPM and DLP with AI, OCR, and predictive analytics; helping organizations detect, label, and protect sensitive data within Google Drive and across all cloud platforms. With Strac, data classification evolves from a static compliance task into a dynamic shield that safeguards business-critical information at scale.
Data classification in Google Drive helps organizations understand what data they store, where it resides, and who can access it. Without classification, sensitive information—like PII, PHI, or PCI—can easily be mismanaged, leading to compliance violations or data breaches. By classifying data, businesses can apply the right controls and prevent unauthorized exposure across shared and private drives.
All of them. PDFs, docs, spreadsheets, zipped archives, images, screenshots, and even CSVs or logs. Strac supports all formats.
Yes. While Google Drive offers native permissions and DLP alerts, it doesn’t deeply inspect file content or automatically classify sensitive information. Strac’s ML/OCR-based system continuously scans both shared and private drives, ensuring proactive protection beyond native coverage.
Continuously; not quarterly or monthly. In today’s fast-moving SaaS environments, files are uploaded, edited, and shared hundreds of times a day. Each of these actions can introduce new risks or alter a file’s sensitivity level. Continuous, automated scanning ensures that any newly added PII, PHI, or PCI data is instantly identified and classified. With Strac, Google Drive data is monitored in real time, so no sensitive file goes untracked; even between user syncs or API integrations.
Accuracy matters, but even the best AI models improve through feedback. That’s why an enterprise-grade platform like Strac allows manual overrides and feedback loops that train its ML models to learn from every false positive or false negative. Each correction strengthens future precision. This adaptive learning ensures that your Google Drive classification framework gets smarter, more context-aware, and increasingly aligned with your organization’s unique data policies over time.
Yes. It is often the first line of defense. By detecting and labeling critical or sensitive files early, Strac helps security teams prioritize protection where it matters most. When ransomware strikes, classified files can be automatically quarantined, restricted from unauthorized downloads, or flagged for immediate action. Similarly, insider threats—whether accidental or malicious—can be detected through anomalous access patterns tied to classified data. In short, intelligent classification gives you visibility and control before threats become breaches.
In Google Admin Console, go to Apps → Google Workspace → Drive and Docs → Labels. Enable classification labels, create your taxonomy, and set default labels. For automated content-based classification, connect a DLP tool like Strac.
Native Google Drive cannot scan file contents for PII or sensitive data. You need Google Workspace DLP (limited regex) or a third-party solution like Strac that uses ML to detect SSNs, credit cards, health records, and custom patterns.
Labels are metadata tags (manual or default). Data classification analyzes actual file contents to identify sensitive data. Labels tell you what someone *thinks* is in a file; classification tells you what *actually* is.
Manual classification: months (and never complete). Automated classification with Strac: initial scan completes in hours for most organizations, with real-time scanning for new files ongoing.






.gif)








